TABLE dateformat(file.ctime,"yyyy-MM-dd HH:mm:ss") as "created" WHERE this.file.name = dateformat(file.ctime,"yyyy-MM-dd")
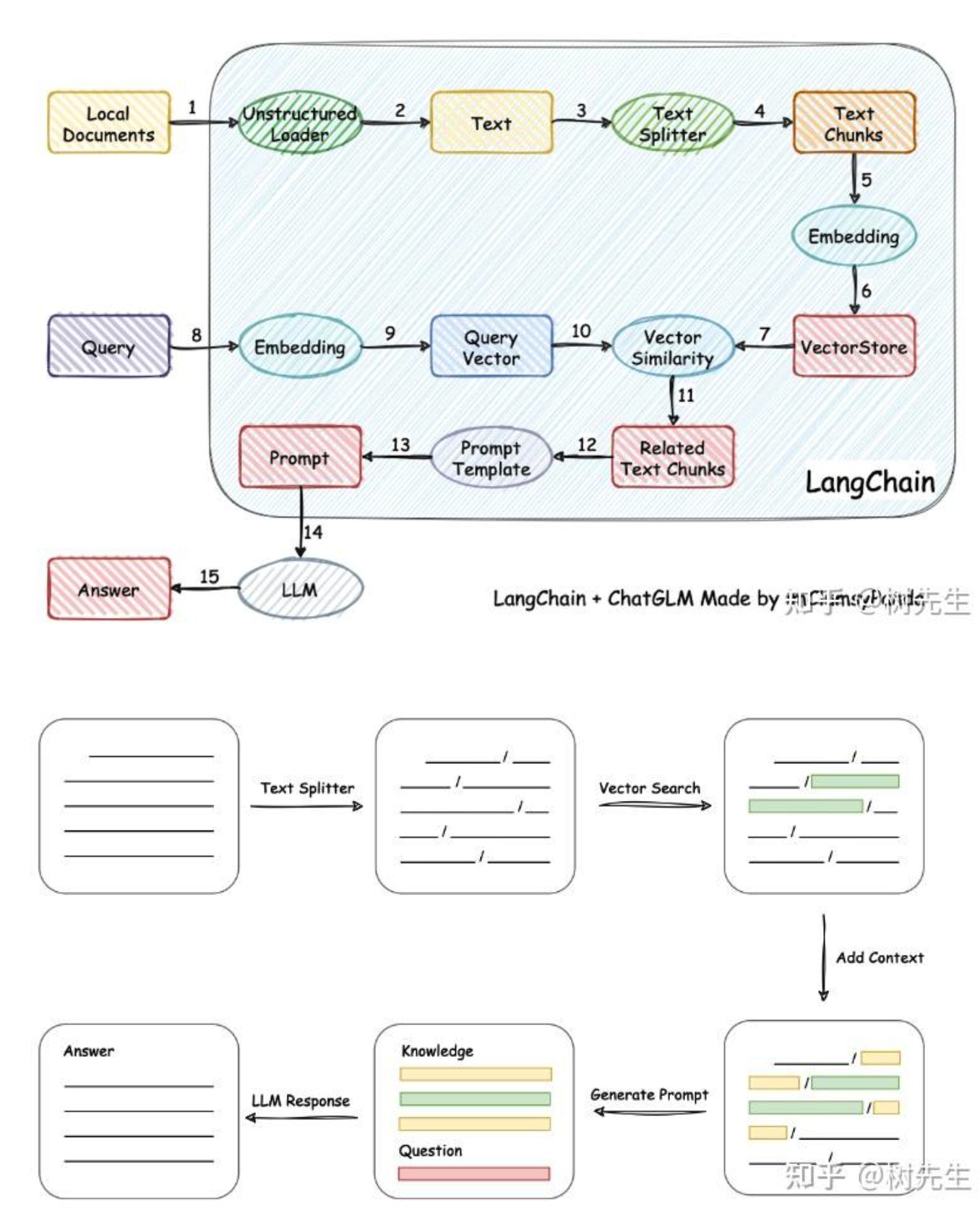
SORT file.ctime ASC通过 OpenAI-embeddings 方式建立知识库搜索
基本上都是用的 GPT-Index 技术,将文本转化为词向量, 然后搜索时,将词向量向数据库中去搜索,得到的反馈后,
- GitHub - openai/chatgpt-retrieval-plugin: The ChatGPT Retrieval Plugin lets you easily search and find personal or work documents by asking questions in everyday language.
- ChatGPT 官方插件 - 检索插件
- fly.io 提供部署服务
- GitHub - gannonh/gpt3.5-turbo-pgvector: ChatGTP (gpt3.5-turbo) starter app
- SupeBase 提供矢量数据库
- LlamaIndex(GPT-Index)使用说明
- LLM Laboratory
- 商用软件,直接提供对接各种类型资源的服务
功能概述
Creating and storing the embeddings:
创建和存储嵌入:
- Web pages are scraped, stripped to plain text and split into 1000-character documents
网页被抓取,剥离为纯文本并拆分为 1000 个字符的文档 - OpenAI’s embedding API is used to generate embeddings for each document using the “text-embedding-ada-002” model
OpenAI 的嵌入 API 用于使用“text-embedding-ada-002”模型为每个文档生成嵌入 - The embeddings are then stored in a Supabase postgres table using pgvector; the table has three columns: the document text, the source URL, and the embedding vectors returned from the OpenAI API.
然后使用 pgvector 将嵌入存储在 Supabase postgres 表中;该表包含三列:文档文本、源 URL 和从 OpenAI API 返回的嵌入向量。
Responding to queries: 回应查询:
- A single embedding is generated from the user prompt
从用户提示生成单个嵌入 - That embedding is used to perform a similarity search against the vector database
- 嵌入用于对矢量数据库执行相似性搜索
- The results of the similarity search are used to construct a prompt for GPT-3
相似性搜索的结果用于构建 GPT-3 的提示 - The GTP-3 response is then streamed to the user.
然后将 GTP-3 响应流式传输给用户。
ChatGPT Token
Managing tokens
Language models read text in chunks called tokens. In English, a token can be as short as one character or as long as one word (e.g., a or apple), and in some languages tokens can be even shorter than one character or even longer than one word.
For example, the string "ChatGPT is great!" is encoded into six tokens: ["Chat", "G", "PT", " is", " great", "!"].
The total number of tokens in an API call affects:
- How much your API call costs, as you pay per token
- How long your API call takes, as writing more tokens takes more time
- Whether your API call works at all, as total tokens must be below the model’s maximum limit (4096 tokens for
gpt-3.5-turbo-0301)
Both input and output tokens count toward these quantities. For example, if your API call used 10 tokens in the message input and you received 20 tokens in the message output, you would be billed for 30 tokens.
To see how many tokens are used by an API call, check the usage field in the API response (e.g., response['usage']['total_tokens']).
Chat models like gpt-3.5-turbo and gpt-4 use tokens in the same way as other models, but because of their message-based formatting, it’s more difficult to count how many tokens will be used by a conversation.
Deep dive
Counting tokens for chat API calls
Below is an example function for counting tokens for messages passed to gpt-3.5-turbo-0301.
The exact way that messages are converted into tokens may change from model to model. So when future model versions are released, the answers returned by this function may be only approximate. The ChatML documentation explains how messages are converted into tokens by the OpenAI API, and may be useful for writing your own function.
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301"): """Returns the number of tokens used by a list of messages.""" try:
encoding = tiktoken.encoding_for_model(model)
except KeyError: encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0301": # note: future models may deviate from this num_tokens = 0 for message in messages: num_tokens += 4 # every message follows <im_start>{role/name}\n{content}<im_end>\n for key, value in message.items(): num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted num_tokens += -1 # role is always required and always 1 token num_tokens += 2 # every reply is primed with <im_start>assistant return num_tokens else:
raise NotImplementedError(f"""num_tokens_from_messages() is not presently implemented for model {model}.
See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")
Next, create a message and pass it to the function defined above to see the token count, this should match the value returned by the API usage parameter:
messages = [
{"role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English."},
{"role": "system", "name":"example_user", "content": "New synergies will help drive top-line growth."},
{"role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue."},
{"role": "system", "name":"example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage."},
{"role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better."},
{"role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable."}, ]
model = "gpt-3.5-turbo-0301"
print(f"{num_tokens_from_messages(messages, model)} prompt tokens counted.") # Should show ~126 total_tokens
To confirm the number generated by our function above is the same as what the API returns, create a new Chat Completion:
# example token count from the OpenAI API import openai
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, )
print(f'{response["usage"]["prompt_tokens"]} prompt tokens used.')
To see how many tokens are in a text string without making an API call, use OpenAI’s tiktoken Python library. Example code can be found in the OpenAI Cookbook’s guide on how to count tokens with tiktoken.
Each message passed to the API consumes the number of tokens in the content, role, and other fields, plus a few extra for behind-the-scenes formatting. This may change slightly in the future.
If a conversation has too many tokens to fit within a model’s maximum limit (e.g., more than 4096 tokens for gpt-3.5-turbo), you will have to truncate, omit, or otherwise shrink your text until it fits. Beware that if a message is removed from the messages input, the model will lose all knowledge of it.
Note too that very long conversations are more likely to receive incomplete replies. For example, a gpt-3.5-turbo conversation that is 4090 tokens long will have its reply cut off after just 6 tokens.