分布式系统中的时钟与一致性解读-腾讯云开发者社区-腾讯云
当我们讨论一致性的时候,我们在讨论什么?
逻辑时间、时钟
1 物理时钟与问题
世界是处于不断变化中的,佛经上说:“诸行无常”,就是这个意思。只有变化,作为观察者的我们才能感觉到时间,正是变化的世界让我们有了时间的概念。
在古代人们使用滴漏来度量时间,现在有了更具有科技水准的原子钟度量时间,而我们最为熟悉的,还是石英钟(包括你的腕表)显示的时间,也就是称为-墙上时钟(WALL CLOCK)的物理时钟。在日常生活中介绍事情时,首先说明时间早已成为惯例。儒家经典、编年体史书《春秋》,用语极为简练,但对时间的记载却贯穿始终。例如隐公元年的记载: “元年,春,王正月” ,通过这段记载,后世史学家便可以很方便的使用西历和后续史书的记载推算出这是公元前722年的春天正月。至于“正月”之前冠“王”字,因为周王为天下权威,一切皆为王有,历法也不例外,所以叫“王正月”。时间与事物的发生高度关联,古已有之。那么在现代,甚至在数据库中,记录事件时包含时钟也就更不足为奇了。
计算机有自己的时钟,它大部分时间和物理时钟相差无几,尤其是配置了 NTP(Network Time Protocol)的计算机还会定期向时钟服务器同步来进行时间校正。这保证了在计算机上记录变化的时间是可信的,例如我们查看各种日志,总会参考他的发生时间。但是在分布式环境中,可能会有计算机的物理时钟与其它计算机的时钟存在差异,这将导致在计算机之间同步消息时,出现对消息发生时间有分歧的情况。
考虑这样一个场景,时钟较快的计算机 C1 上在 T1 时间发生了事件 A1,在经过网络传输到另一台计算机 C2 上。不巧 C2 的时钟远远慢于 C1,即 T2 < T1(T2 为时间达到 C2 时,C2 本地时间),那么 C1 传递的消息 A1 发生的时间 T1 就会令 C2 很困惑,对他来讲,这是一个未来时间发生的事情,颇有穿越之感。NTP 在一定程度上解决了这个问题,但 NTP 仍然存在问题,导致时钟在不同计算机中存在不同步的可能。例如在向 NTP SERVER 同步时钟后,发生了网络阻塞,计算机在获取到 NTP SERVER 时钟时,这个时钟在 NTP SERVER 上已经推进了很多。这就导致不同的计算机仍然存在与 NTP SERVER 存在时钟差异的可能性,这就是时钟不可靠的情况之一。
为什么分布式环境中的计算机对时钟差异这么敏感,尤其是在分布式数据库?主要是我们需要对发生分布式环境中的、在不同计算机上的事件进行排序。而事件的排序决定了后文将要讨论的一致性。准确的对事件按实际发生时间进行排序在单机上非常容易,因为他们共用同一个计时器,可以理解为他们具有同一个观察者,对事件发生的顺序,只要询问这个观察者(本地时钟)就可以了。分布式环境中,每一个计算机都有本地时钟,当对事件的发生时间进行问询时(观察者提问),那么就会出现类似电影《罗生门》的情况,每个节点(计算机)都会根据自己的本地时钟来反馈事件的时间,既然他们的本地时钟不可靠,那他们的反馈又有几分可信呢。如此,自然也就不能就不同计算机上发生的事件根据他们真实发生的顺序(时序)进行排序了。这很难,但并不是没有办法。在分布式系统很难建立全局时钟,在本文中,需要理解: 完美的时钟同步是对于分布式系统是不可行的 ,那么是不是存在其他的方式来实现事件排序呢?
2 逻辑时钟 Logical Clock,LC
为了解决不同机器上的物理时钟难以同步,导致无法区分在分布式系统中多个节点的事件时序问题,也为了区分现实中的物理时钟,Leslie Lamport 于 1978 年在《Time, Clocks and the Ordering of Events in a Distributed System》论文中提出了逻辑时钟的概念,来解决分布式系统中区分事件发生的时序问题。物理时钟不可靠, Lamport 逻辑时钟人为构造一个递增序列来为事件排序,替换物理时钟的递增顺序。 类似于一个并没有怀表的裁判老师在校运动会赛跑终点人为的把参赛学生排出名次,他只是根据自己看到的学生冲线先后进行排序,并没有依靠物理时钟(这种不计时长,只排先后运动会很常见)。在分布式环境中,逻辑时钟解决的是不同节点对事件发生的顺序达成一致,而不是对时间达成一致。从这个角度理解,我们所处的物理世界的时间也就成了逻辑时钟的一个特例了。
逻辑时钟的算法:
- 捕获因果关系(Happened before relation,符号是:→):a → b,代表 a 先于 b 发生,a, b 代表事件
- 逻辑时钟(Logical Clock),用 C 来表示逻辑时钟,逻辑时钟的标准是:
- [C1]: Ci(a) < Ci(b), [ 说明:Ci → 代表逻辑时钟, 如果 a 发生在 b 之前, 那么事件 a 的逻辑时间要小于 b 的逻辑时间, i 代表在 i 这个特定的进程中 ]
- [C2]: Ci(a) < Cj(b), [ 说明:代表不同进程发生的事件逻辑时钟的值 Ci(a) 小于 Cj(b) ]
名词参考:
- 进程(Process):Pi
- 事件(Event):Eij,这里 i 是进程号, Eij 是进程号为 i 的第 j 个事件
- tm:消息 m 的向量时间跨度,表示在进程之间传递
- Ci 向量时钟关联到进程 Pi , 他的第 j 个元素是 Ci[j] ,包含进程 Pi 当前时间的最新值在进程 Pj 中
- d: 漂移时间,通常是 1(即每有新事件发生,进程的逻辑时钟递增 1)
实现规则(Implementation Rules,aka IR):
- [IR1]: 如果 a → b [ 说明:在同一个进程中,事件 a 先于事件 b 发生 ] ,那么, Ci(b) = Ci(a) + d
- [IR2]: Cj = max(Cj, tm + d) [ 说明:如果存在多进程,在进程之间发送事件,tm 等于 Ci(a) 的值,Cj 等于 Cj 和 tm + d 中的最大值 ] ]
实现规则补充说明: 实现规则 1:在同一个线程内,a → b 代表事件 a 先于事件 b 发生,那么事件 b 的逻辑时钟等于事件 a 的逻辑时钟加 d,即 Ci(b) = Ci(a) + d,d 就是漂移时间,也就是逻辑递增值,一般为 1 实现规则 2:在多线程场景中,如果有事件在线程之间发送,那么发送的事件中要携带逻辑时钟,如果线程 i 向线程 j 发送事件 a ,tm 等于需要发送的事件 a 的逻辑时钟 Ci(a),而接收线程 j 则选择 Cj 和 tm + d 中的最大值来更新本地逻辑时钟。
举例说明:
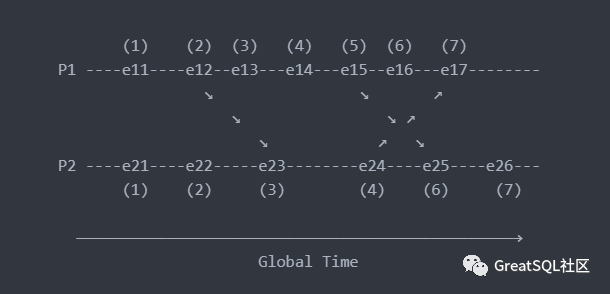
注:e11 指在线程 1 上的第 1 个事件(event) 在上图中:
- 初始值为 1,因为它是第一个事件,并且在起点没有传入值(由其他线程传入的逻辑时钟)
- e11 = 1
- e21 = 1
- 下一个点的值将继续增加 d (d = 1),如果没有传入的值,即适用[IR1]
- e12 = e11 + d = 1 + 1 = 2
- e13 = e12 + d = 2 + 1 = 3
- e14 = e13 + d = 3 + 1 = 4
- e15 = e14 + d = 4 + 1 = 5
- e16 = e15 + d = 5 + 1 = 6
- e22 = e21 + d = 1 + 1 = 2
- e24 = e23 + d = 3 + 1 = 4
- e26 = e25 + d = 6 + 1 = 7
- 当有传入值时,则适用规则[IR2],即取 Cj 和 Tm + d 之间的最大值
- e17 = max(7, 5) = 7, [ e16 + d = 6 + 1 = 7, e24 + d = 4 + 1 = 5, 7 与 5 选择最大值 5 ]
- e23 = max(3, 3) = 3, [ e22 + d = 2 + 1 = 3, e12 + d = 2 + 1 = 3, 3 与 3 选择最大值 3 ]
- e25 = max(5, 6) = 6, [ e24 + 1 = 4 + 1 = 5, e15 + d = 5 + 1 = 6, 5 与 6 选择最大值 6 ]
- 限制
- 适用规则[IR1]时, 如果 a → b, 那么 C(a) < C(b) 正确,即在同一个线程中,事件 a 先于事件 b 发生,那么一定 C(a) < C(b)
- 适用规则[IR2]时, 如果 a → b, 那么 C(a) < C(b) 可能正确也可能不正确。即在不同线程中,线程 1 中的事件 a 的逻辑时钟与线程 2 中的事件 b 的逻辑时钟大小关系不确定,如下图中的 e21,e31 的逻辑时钟先后无法确定

以上介绍参考了: https://www.geeksforgeeks.org/lamports-logical-clock/ 从上面的介绍中可以发现,逻辑时钟是一个正确的算法。MySQL 的用户可能觉得逻辑时钟很熟悉,在 MySQL 的组提交中正是应用了逻辑时钟的方式来解决 binlog 在副本上进行重放时的并发问题。逻辑时钟可以解决事件的偏序问题,但在事件全序上则无法保证。即能够保证存在因果关系的事件的时序,但在不同的节点上不存在因果关系的事件却不符合事件真正发生的顺序。这是因为事件只有在发生因果关系(存在依赖关系)时才会向其他进程发送事件,不存在因果关系的事件之间不存在交互,也就无从知道它们事件的时序。虽然我们从上帝视角可以知道他们的时序,但进程视角的狭隘限制了它。
3 向量时钟 Vector Clock,VC
Lamport 逻辑时钟虽然解决了存在依赖关系的事件时序,但是不同节点同时发生的事件不能很好的进行排序。向量时钟对逻辑时钟进行了继承与发展,它的时钟更新逻辑与逻辑时钟一样。不同在于逻辑时钟只有存在依赖关系的事件才会在节点间发送,而向量时钟则是每一个事件发生后,都会向当前所有节点发送(广播),其他节点接收后,更新本地逻辑时钟,这样就解决了所有事件的依赖关系与时序。
向量时钟的算法: 分布式环境中有 N 个进程,进程有本地的逻辑时间戳。例如,进程 i 的本地逻辑时间 Ti,那么:
- 对于进程 i 来说,Ti[i] 是进程 i 本地的逻辑时间
- 当进程 i 有新的事件发生时,Ti[i] = Ti[i] + 1
- 当进程 i 发送消息时将它的向量时间戳(MT=Ti)附带在消息中。
- 接受消息的进程 j 更新本地的向量时间戳:TJ[k] = max(Tj[k], MT[k]), for k = 1 to N。(MT 即消息中附带的向量时间戳)
假设有事件 A、B 分别在节点 p、q 上发生,向量时钟分别为 T[A]、T[B] 如果 Tq[B] > Tq[A] 并且 Tp[B] >= Tp[A],则 A 发生于 B 之前,记作 A → B,此时说明事件 A、B 有因果关系如果 Tq[B] > Tq[A] 并且 Tp[B] < Tp[A],则认为A、B同时发生,记作 A ←> B
例如下图节点 B 上的第 4 个事件 (A:2,B:4,C:1) 与节点 C 上的第 2 个事件 (B:3,C:2) 没有因果关系,在逻辑上判定为同时发生事件。而 C 节点第 1 个事件 (C=1) 与 B 节点第 1 个事件 (B=1, C=1) 有因果关系,所以 C 节点第 1 个事件 (C=1) 先于 B 节点第 1 个事件 (B=1, C=1) 发生,后者依赖前者,有先后关系。
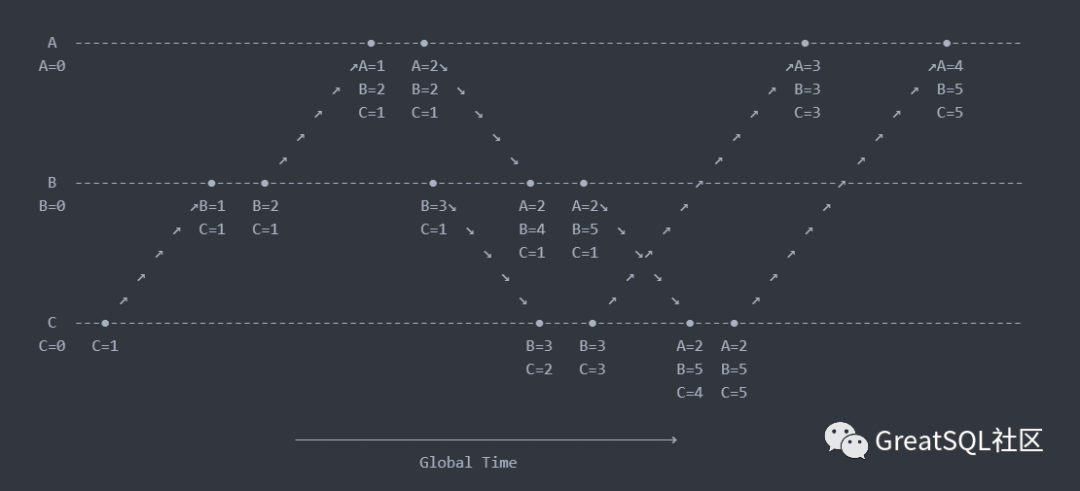
向量时钟算法利用了向量这种数据结构将全局各个进程的逻辑时间戳广播给各个进程,通过向量时间戳就能够比较任意两个事件的因果关系(先后关系或者同时发生关系)。向量时钟被用于解决数据冲突检测、强制因果通信等需要判断事件因果关系的问题。例如在无中心,多写的数据库亚马逊 Dynamo 中就有应用向量时钟。但是因为进程的事件需要向其他节点广播,随着进程数增加,带来了更多空间的要求,更多的逻辑时钟数据结构需要在进程间进行通信,通信成本不低,从图 3 中可以看到一些端倪。
4 TrueTime, TT
TrueTime 是 Google 公司提出的概念,用于在分布式系统中提高物理时钟的可靠性。确切的说这是物理时钟 + 算法,是一种偏向硬件的解决方案,可以分配统一的、具有可比性的 timestamp 范围。在 Google 的 Spanner 上得到了应用。时钟硬件由 GPS 时钟和原子钟组成,因为 GPS 的天线或者接收故障与原子钟的频率导致漂移的故障原因不交叉,可以提高时钟的可靠性。在部署上支持全球部署,在每个数据中心都会部署若干 time master 机器,机器之间会通信校验时间,用于物理时间同步,能够保证 TrueTime 的误差范围 ε 是 1ms 到 7ms 之间。相对于 NTP 的误差范围 100 毫秒大大降低,这是借助硬件和算法实现的。
TrueTime API 的直接数据来源是设备上的 local clock. 所以 TrueTime 的误差来源有:
- 从 time master 同步时的网络延迟, 导致的误差大概是 1ms
- local clock 的漂移, 校准后的一瞬间是 0, 校准前的一瞬间是最大值, 范围在 0~6ms
所以 TrueTime 总的误差在 1~7ms 的范围
TrueTime 提供了三个 API 来操作时间:
| 方法 | 返回 |
|---|---|
| TT.now() | 返回一个区间[earlist, latest], 保证Absolute time(绝对时间)是在区间以内 |
| TT.after(t) | 判断一个时间是否已经成为过去时, 是对TT.now()的简单封装 |
| TT.before(t) | 和TT.after(t)类似,判断时间是否是未来时 |
使用 TrueTime API 时,需要搭配下面两个规则:
- Start:提交事务 Ti 时,事务协调者必须选择一个大于等于 TT.now().latest 的时间作为提交时间戳 si
- Commit Wait:leader 必须等待 TT.after(si)为 true 后才能提交数据,也即必须等待 si 的绝对时间过去了才能提交数据
在具体使用上,举例说明: 分布式系统中有三台服务器 S1、S2、S3,使用 Tabs 来指代绝对时间(绝对时间作为参考系,实际很难获得绝对时间。例如我们看到的事物因为光的传播需要时间,在实际上都属于过去式,典型的,我们看到的太阳是 8 分钟之前的太阳)。在执行分布式事务时,其中一台参与者作为协调者提交事务,提交时使用这次事务所有参与者中最大的时间戳作为事务的提交时间。每台服务器和绝对时间 Tabs 都有误差,这里做出以下假设: S1 的时间比绝对时间快 5ms,即 T = Tabs + 5 S2 的时间比绝对时间慢 4ms,即 T = Tabs - 4 S3 的时间比绝对时间慢 2ms,即 T = Tabs - 2 如下图所示
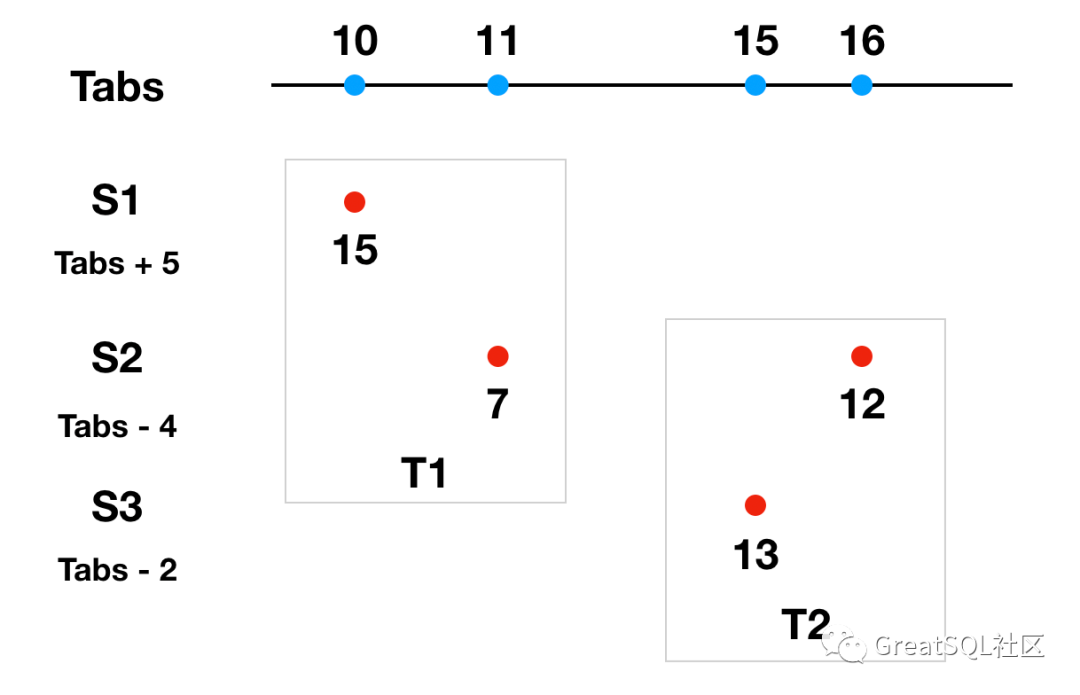
S2 作为协调者发起分布式事务 T1,参与者 S1、S2,S1 执行 T1 本地分支事务时间为 15ms (此时 Tabs 为 10ms), S2 执行 T1 本地分支事务的本地时间是 7ms(此时 Tabs 为 11ms),S2 作为协调者需要选择参与者中时间最大成员时间作为提交时间,所以选择 S1 的 15ms 作为提交时间。
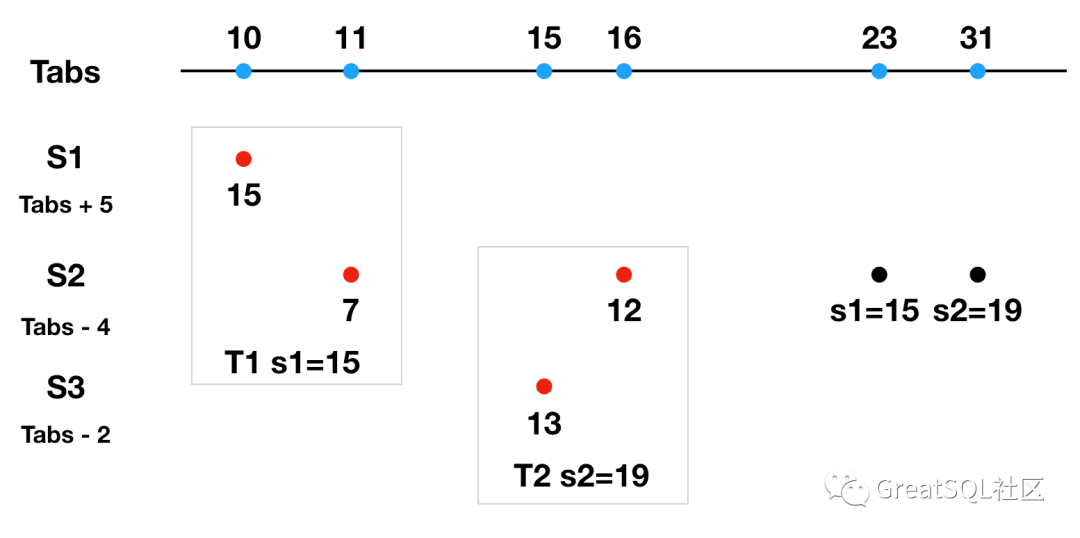
S2 作为协调者又开启了分布式事务 T2,参与者包括 S2、S3,S3 执行本地分支事务的时间是 13ms(此时 Tabs 为 15ms),S2 执行本地分支事务的时间是 12ms(此时 Tabs 为 16ms)。S2 还是作为协调者,提交事务时选择了 13ms 作为整个事务的执行时间。
在绝对时间上可以看出 T2 是在 T1 之后提交的,但是在事务本身选择的时间上看出 T1 比 T2 晚提交,这违反了事务原本的提交顺序(需要保证 T2 晚于 T1 的提交时间这一物理事实),也对一致性产生影响。在上图示例中没有使用 TrueTime API 的两个规则,那么来看看 TrueTime 是如何解决这个问题的呢。继续使用上面的示例,但需要考虑一个因素,即:假设 TrueTime 误差 ε 为 7ms。 S2 作为协调者在提交 T1 选择提交时间 s1 时,根据 Start 规则需要大于所有事务参与者(此时是 S1、S2)最大的本地时间,并且需要大于 S2 本地的 TT.now().lastest (即 TT.now() + ε),所以 s1 = max(15, 7 + 7) = 15ms。 s1 确定后,根据 Commit Wait 规则,还要等待 TT.after(15) 为 true 后(即在误差时间 7ms 后,才能确认 s1 是过去时间,此时 S2 本地时间是 23ms)才能提交数据。也就是 TT.now() 是在[16, 30]区间的,S2 的本地时间是 23ms ,绝对时间 27ms 提交数据。
S2 作为协调者在提交 T2 选择提交时间 s2 时,根据 Start 规则得出 s2 = s2 = max(13, 12 + 7) = 19ms。 s2 确定后,根据 Commit Wait 规则,还要等待 TT.after(19) 为 true 后(即在误差时间 7ms 后,才能确认 s2 是过去时间,此时 S2 本地时间是 27ms)才能提交数据。也就是 TT.now() 是在[20, 34]区间的,S2 的本地时间是 27ms ,绝对时间 31ms 提交数据。
通过加入 Start 和 Commit Wait 两个规则后,无论是事务自己选择的时间戳还是绝对时间,事务 T1、T2 的最终提交顺序都是 T2 晚于 T1,符合他们真实的提交顺序。解决了提交顺序问题,同时满足一致性要求。这里面没有考虑加锁释放锁的逻辑,从中可以看出事务提交额外引入了等待机制,需要等待 TrueTime 时间误差 ε 才能提交,这对性能必然有影响,所以 Google 一直在致力于提高 TrueTime 的精确度来降低误差 ε 。TrueTime 还是属于物理时钟的解决方案,除了 Spanner,TIDB 采用了和 Oracle 相似的 TSO 授时来为事务分配全局唯一的时间戳,也属于物理时钟的一种解决方案。因为时钟精确度以及网络开销问题,TiDB 适合在网络相对有保证的机房内部署(需要向 PD 来请求时钟),而不是像 Spanner 那样,支持全球部署,有 GPS 加持的地方,就可以有 Spanner。详细内容可参考: http://yang.observer/2020/11/02/true-time/ 或论文 Spanner: Google’s Globally-Distributed Database
5 混合逻辑时钟 Hybrid Logical Clocks,HLC
Lamport 逻辑时钟解决了分布式环境中物理时钟不能精确同步时,对存在依赖关系的事件进行排序的问题。但在全序上对同时或者无依赖关系的事件却不能准确的进行排序。向量时钟虽然解决了逻辑时钟的全序排序问题,却引入了空间占用较大、通信成本高的问题。单纯使用逻辑时钟或者物理时钟(需要硬件支持)的解决方案都不尽完美。既然逻辑时钟可以解决分布式环境中事件精确的因果关系(这里的因果关系指的是其在真实物理时间上的顺序),物理时钟直观,且可以解决数据库要求的时间点备份恢复问题,那么将逻辑时钟与物理时钟结合起来的方案是否可行。在 2014 年,五位数据库行业先贤(Sandeep Kulkarni, Murat Demirbas, Deepak Madeppa, Bharadwaj Avva, and Marcelo Leone)发表了论文《Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases》,提出了 Hybrid Logical Clocks 的方案。整合了逻辑时钟与物理时钟,支持对事件进行因果关系排序,同时又有物理时钟直观的特点。
混合逻辑时钟即混合了物理时钟和逻辑时钟,实质上,是对逻辑时钟的增强。物理时钟是机器本地的时钟 PT(Physical Time,例如 NTP clocks),系统时间可能会比墙上时钟稍快或稍慢,在一天之内误差可能有毫秒甚至秒级。逻辑时钟是通过 happened-before 关系确定事件的逻辑时钟 LC ,从而确定事件的偏序关系。在分布式场景下,使用物理时钟和逻辑时钟的共同的递增来确定事件的因果关系。后续介绍中更多的引用了论文《Logical Physical Clocks》中的概念与内容。
5.1 概念预介绍
分布式系统由节点(node)集合组成,节点数量会随着时间推移而发生变化,节点从事件角度来看会执行三种类型的事件,接收事件、发送事件、本地事件。时间戳算法目的是为每一个事件分配一个时间戳。在混合逻辑时钟算法实现上,使用 lc.e 来表示分配给事件 e 的逻辑时钟时间戳。和上文介绍的一样,使用 happened before hb 来表示系统中的两个事件的因果关系。按照这个规则, e hb f 表明: 事件 e 与事件 f 发生在同一个节点,并且事件 e 先于事件 f 发生或者事件 e 是发送事件,事件 f 是相应的接收事件 e || f 表明: 事件 e 与事件 f 同时发生(并发) 根据规则,可以推断出: e hb f ⇒ lc.e < lc.f lc.e = lc.f ⇒ e || f e hb f ⇐> vc.e < vc.f
5.2 算法介绍
HLC 的目标是提供类似于 LC 的单向的(one-way)因果关系检测,同时保持时钟值始终接近物理时钟。HLC 需要保证能够满足以下四个要求:
|
|
论文原文
|
释义
|
| --- | --- | --- |
|
1
|
e hb f ⇒ l.e < l.f
|
如果 e 事件先于 f 事件发生(e happened before f),那么 l.e 一定小于 l.f,也就是满足因果关系
|
|
2
|
Space requirement for l.e is O(1) integers
|
可以使用一个整数存储,不会随着分布式系统中节点数的增加而增加。(向量时钟会随着节点数的增加而增加)
|
|
3
|
l.e is represented with bounded space
|
l.e 的值不会无限增长。(这点和 Lamport 逻辑时钟不一样,Lamport 逻辑时钟会无限增长)
|
|
4
|
l.e is close to pt.e, i.e., | l.e - pt.e | is bounded
|
l.e 的值和 e 事件发生的物理时钟值 pt.e 接近, | l.e - pt.e | 的值会小于一定的范围
|
5.2.1 Naive Algorithm
给定的目标 l.e 的值和 e 事件发生的物理时钟值 pt.e 要接近,在 Naive Algorithm 算法中我们定义一下规则:对于任何事件 e,它的混合逻辑时钟的物理时钟部分要大于等于本地物理时钟,即 l.e >= pt.e 。设计的算法如下:
- 初始化所有 l 设置为 0
- 发送事件或本地事件 f, f 是在节点 j 上创建的,设置 l.f = max(l.e + 1, pt.j),事件 e 是节点 j 的前一个事件,确保 l.e < l.f 同样确保 l.f >= pt.f
- 接收事件_f_, f 是在节点 j 上创建的,设置 l.f = max(l.e + 1, l.m + 1, pt.j), l.e 是节点 j 的前一个事件时间戳,l.m 是发送事件的时间戳,这确保 l.e < l.f 和 l.m < l.f
简化逻辑如下:
- 初始化:l.j = 0
- 发送消息事件或者本地事件:l.j = max(l.j + 1, pt.j)
- 接收 m 消息事件:l.j = max(l.j + 1, l.m + 1, pt.j)
很容易看出算法符合上面需要满足的四个要求中的1和2,但不满足3和4。举例说明,其并不满足 | l.e - pt.e | 在一定范围内。
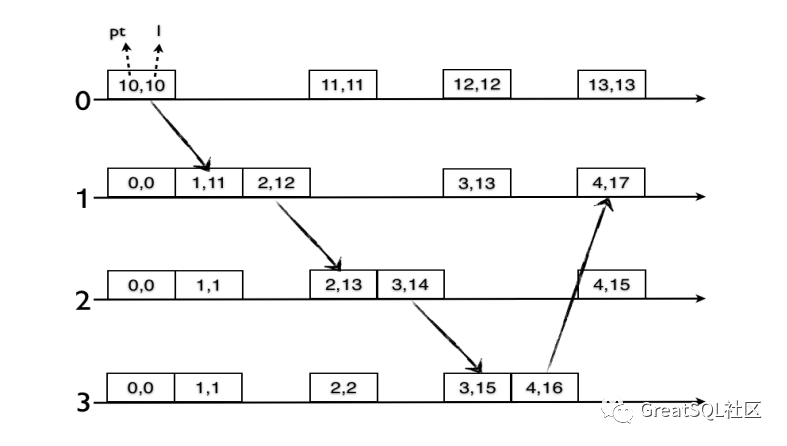
上图是一个计数的例子(counterexample),消息在节点 1,2 和 3 之间循环,永久重复,每循环传递回合,逻辑时钟与物理始终之间的漂移(l - pt)将会保持增长。消息再次到节点 1 时,| l - pt | 为 17-4=13,随着事件的继续传递,物理时钟和逻辑时钟的漂移会越来越大,这明显不符合要求 3 和要求 4。这是因为,虽然在 Lamport 逻辑时钟的基础上引入了物理时钟,但是却不能分辨出这个值增长究竟是物理时钟导致的还是逻辑时钟增长导致。这样即使物理时钟的增长追赶上了逻辑时钟的增长,我们也没办法重置逻辑时钟部分的值,所以这个算法并不可行。
5.2.2 HLC Algorithm
为了解决上述问题,HLC algorithm 算法把 Naive Algorithm 算法中的 l.j 扩展为逻辑时钟与物理时钟两个部分: l.j 和 c.j 。第一部分 l.j 引入来维护到当前为止最大的物理时钟 pt,第二部分 c.j 则用来表示逻辑时钟部分,当几个事件的物理时钟相等时,使用 c.j 来表示事件之间因果关系(capture causality updates)。对比 Naive Algorithm 算法,不违反先序关系(hb, happened before)时没有合适的地方来重置逻辑时钟 l ,在 HLC Algorithm 算法中,当节点本地物理时钟 pt 赶上或超过 HLC 的物理时钟部分 l.j ,就可以重置逻辑时钟 c.j 了,并把 l.j 更新为新的本地物理时钟。由于 l.j 表示能够感知到的最大物理时钟,而且不随每个事件而递增,在一定的时间范围内,做出以下保证:
- 节点接收消息,使用较大的物理时钟 l ,其 l 已更新,逻辑时钟 c 重置来反映这一点
- 如果节点没有接收其他节点消息, 那么他的混合逻辑时钟的物理时钟部分 l 将会保持不变, 并且他的本地物理时钟 pt 追赶上并更新混合逻辑时钟的物理时钟部分 l, 并且重置逻辑时钟部分 c 。
如下是算法的描述: 初始化时,物理时钟部分 l 逻辑时钟部分 c 设置为 0。当一个发送事件 f 被创建,物理时钟部分 l.j = max(l.e, pt.j), 事件 e 是 j 节点上前一个事件,初始时并不存在,所以第一个事件的混合逻辑时钟的物理时钟部分就是本地物理时钟。类似于 naive algorithm 算法,这确保 l.j >= pt.j (即 HLC 的物理时钟部分要大于等于节点本地物理时钟)。因为移除了 “+1” 的自增逻辑,,存在 l.e = l.f 的可能。为解决这种情况, 利用逻辑时钟部分 c.j 。通过增加 c.j ,能够确保( l.e, c.e) < ( l.f, c.f ) 结果为真。如果 l.e 与 l.f 不同,那么 c.j 需要被重置, 这将保证逻辑时钟部分 c 有界,即逻辑时钟是在一个可预测的范围内。当一个接收事件被创建,设置物理时钟部分 l.j = max(l.e, l.m, pt.j) 。现在,取决于 l.j 是否等于 l.e 和接收的事件 m 的物理时钟部分 l.m , c.j 都会得到设置。简而言之,就是本地 HLC 时钟会根据本地的事件或者接收的事件,亦或者本地物理时钟来推进。简化算法逻辑如下图:

上图是算法的一个展示。在发送事件的逻辑中, l’.j 指的是 j 节点当前最近执行的事件的物理时钟。当发送事件 f 创建时,物理时钟部分在当前节点本地执行最新的事件 e 的 HLC 的物理时钟部分 l.e 和节点本地最大物理时钟 pt.j 两个之中选择最大值,设置为发送时间的 HLC 的物理时钟 l.j 的值。至于发送事件 HLC 的逻辑时钟部分则取决于事件 e 与发送事件 f 的 HLC 的物理时钟部分是否相等,相等则发送事件 f 的 HLC 的逻辑部分等于事件 e 的逻辑时钟部分 c.j + 1 ,如果不相等,则发送事件 f 的 HLC 的逻辑部分则被重置为 0。最终得到 HLC 的两部分值与接收事件的逻辑大同小异,详细参考上图中逻辑。下图是计数(counterexample)例子按照 HLC 算法调整的一个具体的示例:
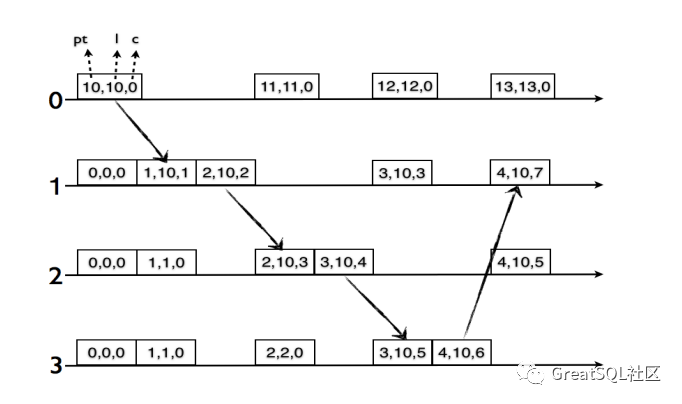
在上图中,当继续在1,2,3节点间的循环,可以看到在节点1上 pt 在追赶并超过 l.j = 10 ,并且重置了逻辑时钟部分 c.j = 0。后续节点间传递消息时,因为节点的 pt 较小,可以看出一直在追赶 HLC 的物理时钟,并且在 HLC 物理始时钟相等时,仅仅增加逻辑时钟部分,直到节点 1,2,3 中任何一个的本地物理时钟值超过 10,这时会将 c.j 重置为 0。
通过算法改进,把物理时钟和逻辑时钟分开来表示,满足了上边的四个要求中的3和4。HLC 仍然需要 NTP。对于任何一个事件 j,pt.j ⇐ l.j ,也即 HLC 的物理时钟部分的值一定大于等于本地物理时钟(通过 NTP 同步)值。假设整个分布式系统中,NTP 协议的时钟误差值为 ε 。新算法中,对于任何一个事件 j,| l.j - pt.j | ⇐ ε,也就是 HLC 物理部分的值和本地物理时钟值的差距不会超过 ε。NTP 协议的误差值在局域网内大概 1 毫秒内,广域网可能达到 100ms 或更大。所以一般情况下,使用 HLC 时节点本地物理时钟与 HLC 的物理时钟部分的误差会在 100ms 级别。HLC 虽然没有像 TrueTime 那样需要硬件依赖,但 HLC 仍然有一个 bound(有界) 的要求,需要保证 | l.e - pt.e | 在这个 bound 范围内,如果超过了这个 bound,HLC 就不能正常工作了。这也是需要在分布式系统中部署 NTP 的原因之一。
在工程实践中,HLC 一般会使用 8 字节 64 比特来表示,高位 48 比特是以毫秒为单位的物理时间。低位 16 比特是一个单调增长的整数,最大 65535。目前像 CockRoachDB、 MongoDB 都使用了 HLC 算法,CockRoachDB 在分布式事务中使用了 HLC , MongoDB 则依靠 HLC 支持了因果一致性。
6 一致性
用了很大篇幅在说时钟,时钟解决了事务(或者叫事件)的顺序关系,那么也就提供了一致性保证。那么具体什么是一致性?在不同的语境,一致性可能是不同的。
6.1 理论中的一致性
ACID 之 Consistency 在电影《菊次郎的夏天》中有一幕,放暑假的留守男孩正男与废柴大叔菊次郎在一场治愈之旅中遇到了机车兄弟和章鱼男,一行人做了一个游戏(一二三木头人),这里面的小朋友正男站立不动,其他人在后面慢慢接近,正男每次回头,所有人不能让正男看到移动动作,如果被看到移动动作,则出局。电影的配乐、久石让的 Summer 灵动活泼,清新自然,让人听来舒心放松,这个游戏也让人联想到事务特性中的一致性,正男作为用户(观察者)不能看到其他人移动的动作(中间状态),虽然几人每次位置(为接近正男)有变化,但其动作不为观察者捕获。也就是从一个一致状态到下一个一致状态,即不允许用户看到不一致的状态。这就是 ACID 中的一致性。
CAP 之 Consistency CAP 中的 Consistency 是在一致的状态之外增加了原子性的要求,是一种强一致性要求。它的一致性结果的要求则是线性化的,这在分布式系统中很难实现。异步系统中,可用性不可能满足,主备节点切换总是需要时间。存在网络分区时,无法同时保证可用性与一致性,于是有了 AP 和 CP 系统的艰难选择。所以为了保证可用性,正经分布式数据库很难支持线性一致性。
BASE 之 Eventual Consistency BASE 的基本可用、柔性状态、最终一致性,是对 CAP 的要求进行了弱化,比较多的场景对性能的要求还是要高于一致性的要求,用户体验是一些应用赖以生存的根本。更新异步的在系统中传播,较强的的一致性延迟较大,明显降低用户体验,所以降低为最终一致性,提升用户体验,占领市场才是硬道理。但是最终是什么时候?一个转账请求,在较弱的一致性场景下,如果是由流处理系统来操作的,那么只有请求在流处理队列中被处理后,用户才能看到,达到最终一致性。现实中转账需要两个小时到账的例子不胜枚举。而这个两个小时就是最终一致性的一种“最终”保证,听起来不可靠,但可以工作得很好。
6.2 分布式系统中实现的一致性
从另一个角度讲,一致性更多的是在描述读一致性。在分布式系统中,采用副本冗余保证高可用是普遍的做法,在向系统写入数据后后,能否承诺立即读取到最新的值,是一致性级别的重要体现。
严格一致性 在这模型下,包含了全局时钟概念,任何进程的写入都可以在写入后立即被其他进程读取,就需要保证写入被复制到所有副本,保证不能被回滚。这只是一个理论模型,限于分布式限制以及事情发生传播的速度,这不可能实现。
可线性化(线性一致性 Linearizability) 要求对分布式系统中不同节点的发生的事件的排序类似在单机系统中是一样的顺序,一样的一致性结果。可线性化是单对象、单操作最强一致性模型。写操作在开始和结束之间的某个时间点,写操作的效果 严格一次性 对所有的读取者可见。即写入的可见性需要对所有观察者有同样的保证。线性化既保证在进程局部中的操作顺序,也保证其他进程的并行操作的顺序。这个顺序是一致性的,也就是每次读取应该返回在此之前的最新值。即使存在并发,读取也应该以一种看似连续的效果呈现。这里借用《Database Internals: A deep-dive into how distributed data systems work》中的示例来说明。三个进程,进程 1,进程 2,进程 3 各自执行了以下操作
| 进程1 | 进程2 | 进程3 |
|---|---|---|
| write(x, 1) | write(x, 2) | read(x)read(x)read(x) |
如下图所示,write(x, 1)表示设置寄存器 x=1,寄存器初始值为Ø(表示为空集)。read(x)表示读取寄存器 x 值,这里隐含着三个线程使用了相同的时钟,横向即为时钟演进方向。线段长短代表指令执行时长。
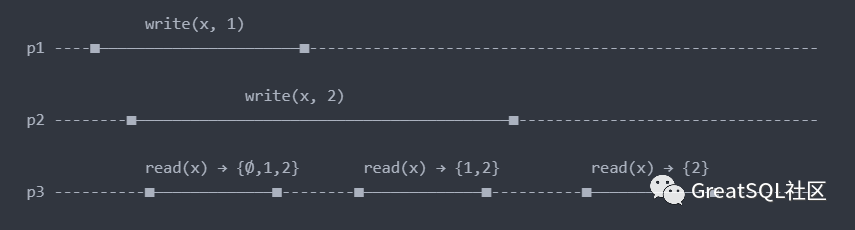
线程 3 的三次读取:
- 第一次读取时,写入仍在进行中,所以读取的结果并不确定,读取的结果可能是Ø,可能是 1,也可能是 2。那么在事件排序上,第一次读取可以排在线程 1 和线程 2 写操作之前,也可以排在线程 1 和线程 2 写操作之间,也可以排在两次写操作之后。
- 第二次读取时,线程 1 的写操作已经完成,线程 2 写操作仍在继续,所以返回值可能是 1,也可能是 2。
- 第二次读取时,线程 1 和线程 2 的写操作都已经完成,所以只能返回 2。这是因为线程 2 的写操作需要排在线程 1 的写操作之后。
可线性化体现的就是可见性,操作一旦完成,所有观察者都能够看见。操作虽然不是原子的,但在某个时刻(可线性化点),它一旦变得可见,就是对所有成员而言。正如上文所说,正经分布式数据库很难支持线性化,这是基于代价而言,而不是技术难度。要实现线性化,所有的写入都要同步得到系统中的所有节点后才返回,这带来显著的延迟,就这一项,就很难被用户接受。
即然是全局有序,在这里就可以使用全局时钟来实现线性化,完全可以采用 TrueTime 或者 Oracle 的全局授时算法来对分布式系统中的事务分配时间戳。当然在并行过程中还存在冲突的可能性,需要引入共识算法来解决冲突并排序,来支持线性一致性。
顺序一致性(Sequential Consistency) 虽然在语义上经常与线性一致性混淆,但顺序一致性是对线性一致性放宽要求的一种模型,仍然具有相当强的一致性保证。最早则是用来描述 CPU 的行为,在默认情况下,多核 CPU 并不能保证顺序一致性,需要使用内存屏障来确保写入操作对并发线程按顺序可见。CPU 是可以重新排序命令的,如果可以找到一个所有 CPU 执行指令的排序(Order),该排序中每个 CPU 要执行指令的顺序得以保持,且实际的 CPU 执行结果与该指令排序的执行结果一致,则称该次执行达到了顺序一致性。这里使用多核 CPU 执行指令的例子说明,这同样可以类比数据库多节点写入的情况:
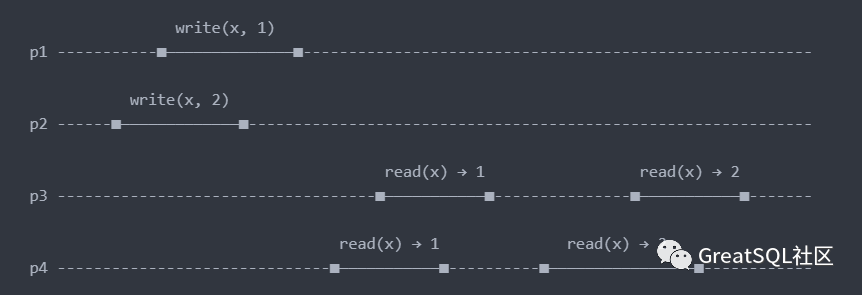
上图中的 write(x, 1) 代表将 1 写入 x,read(x) → 1 代表读取 x 值为 1。横向代表时钟演进方向,即时间。线段长短代表指令执行时长。对上图的执行结果进行了一次重排序(Reordered): p1: write(x, 1) → p3: (read(x) → 1) → p4: (read(x) → 1) → p2: write(x, 2) → p3: (read(x) → 2) → p4: (read(x) → 2) 排序中各个 CPU 的指令顺序得以保持(如 p3: (read(x) → 1 在 p3: (read(x) → 2 之前),这个排序的执行结果与 CPU 分开执行的结果一致,因此该 CPU 的执行是满足顺序一致性的。另外从图中可以看出,p2: (read(x) → 2) 实际上是在 p3: (read(x) → 1) 之前完成的,但是 p3 读到的仍然是 (x → 1) ,这其实是符合实际情况的,毕竟 p2 的写入传播到 p3 需要时间。从重排序中注意到顺序一致性关心的是 CPU 内部执行指令的顺序,而不关心 CPU 之间的相对顺序。延伸到分布式系统中,每个进程都可以按照自己指定的顺序发出读写请求,任何单线程的程序其实都是一个接一个的执行自己的步骤。从同一个进程传播出来的所有操作都应该按照它的提交顺序出现。来自不同的线程的操作则可以任意排序,从观察者(读者)角度来看,这就是顺序一致性。从上图 CPU p3、p4 的操作在重排序后也可以看出来。
Zookeeper 就描述它支持顺序一致性,Zookeeper 所有的写入都会转发到他的 Leader 节点,Follower 节点从 Leader 节点复制数据。这与 Raft 类似,Zookeeper 的 Leader 节点充当了状态机的角色,所以 Follower 节点的写入顺序会和 Leader 节点一致,但是 Zookeeper 允许从 Follower 节点读取数据,在读取 Follower 节点数据时,Leader 节点的数据有可能还没有同步到 Follower 节点,这样,顺序一致性就得不到保证了。
因果一致性 在全局对所有操作进行排序,成本较高,很多时候也没必要。在一些有依赖关系的操作之间建立关系则是有必要的。虽然没有全局排序的必要,但是需要满足一个要求: 在所有的过程(或者叫观察者)中,必须以相同的顺序看到有因果关系的操作 。你在网上发出一条微博,有人回复了这条微博。那么第三人看到的顺序应该是,你先发了微博,然后有人回复了微博。而不是先看到一条回复,然后才看见你的微博。发出微博和回复具有明显的依赖关系,其他人也应该以发出微博,然后评论的顺序看到,操作的因果关系对所有的观察者以相同的顺序呈现,这就是因果一致性模型。
如果不满足因果一致性,会产生什么影响?

在上图中,进程 p1 和 p2 进行了无因果顺序的写入,他们的写入无序的传播到其他进程,进程 p3 先看值 1,在看到值 2,而进程 p4,却首先看到值 2,再看到值 1。进程 p3 与进程 p4 看到的时间顺序并不一致,如果两个写入操作没有依赖关系,那么这种病情况并无大碍,如果存在依赖关系,操作无序的传播就会引起一致性的问题。
在上图中,如果建立因果关系,就需要在进程 p1 和 p2 的写入之间指定一个逻辑时钟,来指定两个写入之间的因果顺序。如下图
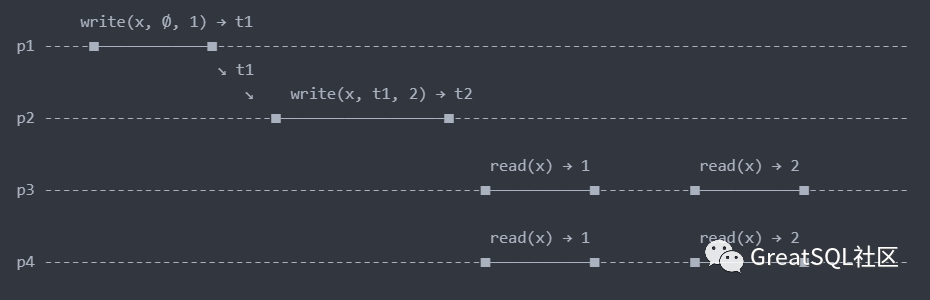
在这里可以把 x 值变化看作是状态的变化。p1 线程将 x 的状态由Ø(空集)设置为 1,逻辑时钟此时为 t1。进程 p2 执行的 write(x, t1, 2)操作,指定他是在 t1 之后,与进程 p1 执行的操作存在按逻辑时钟建立的因果顺序。虽然进程 p1 的操作和进程 p2 的操作在传播速度上不同,即使进程 p2 的操作先传播到进程 p3,但是因为它依赖的操作 write(x, Ø, 1)暂时并没有到达,所以 write(x, t1, 2)的操作是不可见的。这样,使用逻辑时钟就解决了存在依赖关系的操作的排序问题。
使用逻辑时钟解决了因果操作的排序,但是并不能解决数据库通常的按时间点的备份,例如我们要对数据库执行一份一个小时前的备份,这是有一个精确时间点要求的。逻辑时钟只解决了上图进程 p1 和进程 p2 的排序,但是没能记录操作具体是什么时间(物理时钟)执行的,在执行精确的时间点备份时,就无法判断备份需要截至到在那个操作了,这就需要混合逻辑时钟了。需要在逻辑时钟之中增加物理时间。
MongoDB 就是基于混合逻辑时钟在 MongoDB 3.6.4 支持了因果一致性(Causal Consistency),并骄傲的表示:MongoDB is one of the first commercial databases we know of which provides an implementation [of causal consistency]。详细可以参考论文:Implementation of Cluster-wide Logical Clock and Causal Consistency in MongoDB,在附录部分,给出了混合逻辑时钟的实现证明。
可调一致性 前文说过,分布式系统通常采用副本冗余的方式来维护高可用。采用复制架构的数据库,在主节点写入,数据同步到其他副本则需要时间,一般是异步写入(MySQL 的半同步则是写入副本的中继日志)。如果使用读写分离,一致性就很难保证。在数据复制中,引入三个变量来调节写入、读取: 复制副本数:N ,数据副本的数量写入一致性:W ,写入成功时需要确认的副本数读取一致性:R ,读取成功时需要响应的副本数在写入时,选择给客户端返回成功标志的时机对一致性有不同的影响。写入一个副本(即主节点),写入一致性 W = 1 ,通知客户端写入成功。此时写入尚未同步到其他副本,如果客户端据此向其他副本发出读请求,将不能返回最新值。这是 RYW(Read Your Write)的例子。即使此时客户端从主节点读取最新的值,但如果此时,主节点崩溃,其他副本接替崩溃节点的工作。因为崩溃节点的最新值没有同步到其他副本,此时客户端再次发起读请求,在之前尚能读取到的最新值,此时却不见了,仍然违反一致性。所以只写入一个副本就通知客户端成功,是较弱的一致性保证。MySQL 的半同步复制在一定程度上解决了这个问题,但只是保证主节点的写入能写入到从节点的磁盘,并没有在实例中应用。
如果写入一致性与读取一致性变量满足 W + R > N ,系统则可以保证每次读取总能够返回最新值,满足 RYW(Read Your Write)的要求。因为读取的副本和写入的副本总是存在交集,保证总会读取到包含最新值副本。例如一个含有 5 副本的数据库,在主节点写入后,在写入同步到 3 个副本后返回,那么我们从其中的 3 个副本中读取,至少能够保证其中一个副本中包含最新写入的值。
最好的一致性写入,毫无疑问是等待写入同步到所有节点后再通知客户端写入成功。也就是设置 W = N ,那么读取一致性即使只设置为 R = 1 ,也能保证读取到最新值,即使回滚也没有影响,因为副本中已经全部包含了新写入的值。但是这需要接受较大的延迟,写入一致性变量 W 越大,则延迟越高,一致性保证越好。不能接受延迟,或者对一致性要求并不高,则可以设置 W = 1,或者一个较小的值,配合设置读一致性 R 为一个较大的值(保证 W + R > N)来保证一致性,此时的延迟则加大,因为需要等待数据同步到大部分副本,可以看出这是一个 Trade off。
MongoDB 实现了可调一致性,通过在写入时设置 writeConcern,在读取时设置 readConcern 来调节一致性,这是一种非常灵巧的方法,而且将选择性交给用户,既然选择强一致性,那么就需要接受较大的延迟。
7 多说一点
不同的数据库对一致性有不同的保证,他们使用了不同的时钟来对操作进行排序,从 TrueTime 的 Spanner,到使用混合逻辑时钟的 MongoDB,在实现一致性时都对延迟有所妥协。这种折中、妥协在计算机设计中比比皆是。通过本文的描述,希望能引起大家的兴趣,投入到分布式数据库领域中来,来见证分布式数据库的成长。