const currentPage = dv.current().file;
const dailyPages = dv.pages('"0-Daily"').sort(k=>k.file.name, "asc");
const currentPageName = currentPage.name;
const index = dailyPages.findIndex((e) => {return e.file.name === currentPageName});
if (index < 1) {
dv.table(["File", "Created", "Size"],[]);
} else {
const lastIndex = index - 1;
const lastPage = dailyPages[lastIndex].file;
const allPages = dv.pages().values;
const searchPages = [];
const lastTime = dv.parse(lastPage.name);
const currentTime = dv.parse(currentPage.name);
for (let page of allPages) {
const pageFile = page.file;
if (pageFile.cday > lastTime && pageFile.cday <= currentTime) {
searchPages.push(pageFile);
}
}
dv.table(["File", "Created", "Size"], searchPages.sort((a, b) => a.ctime > b.ctime ? 1 : -1).map(b => [b.link, b.ctime, b.size]));
}
模糊照片 AI 修复
DiffBIR 一种基于生成扩散的高质量图像修复技术,可以从非常低质量的原图生成高清修复图。
论文:https://arxiv.org/abs/2308.15070
GitHub 页面:https://github.com/camenduru/DiffBIR-colab…
项目页面:https://0x3f3f3f3fun.github.io/projects/diffbir/…
Colab 在线运行: https://github.com/camenduru/DiffBIR-colab

Vercel 推出的 AI 前端工具 v0
v0 是什么
v0 是 Vercel 推出的一款 「前端组件代码生成工具」 ,当前还处于 Alpha 阶段,要想试用需要先排队。
他的使用方式如下:
- 首先,用自然语言描述需求

v0 会根据需求生成组件代码:
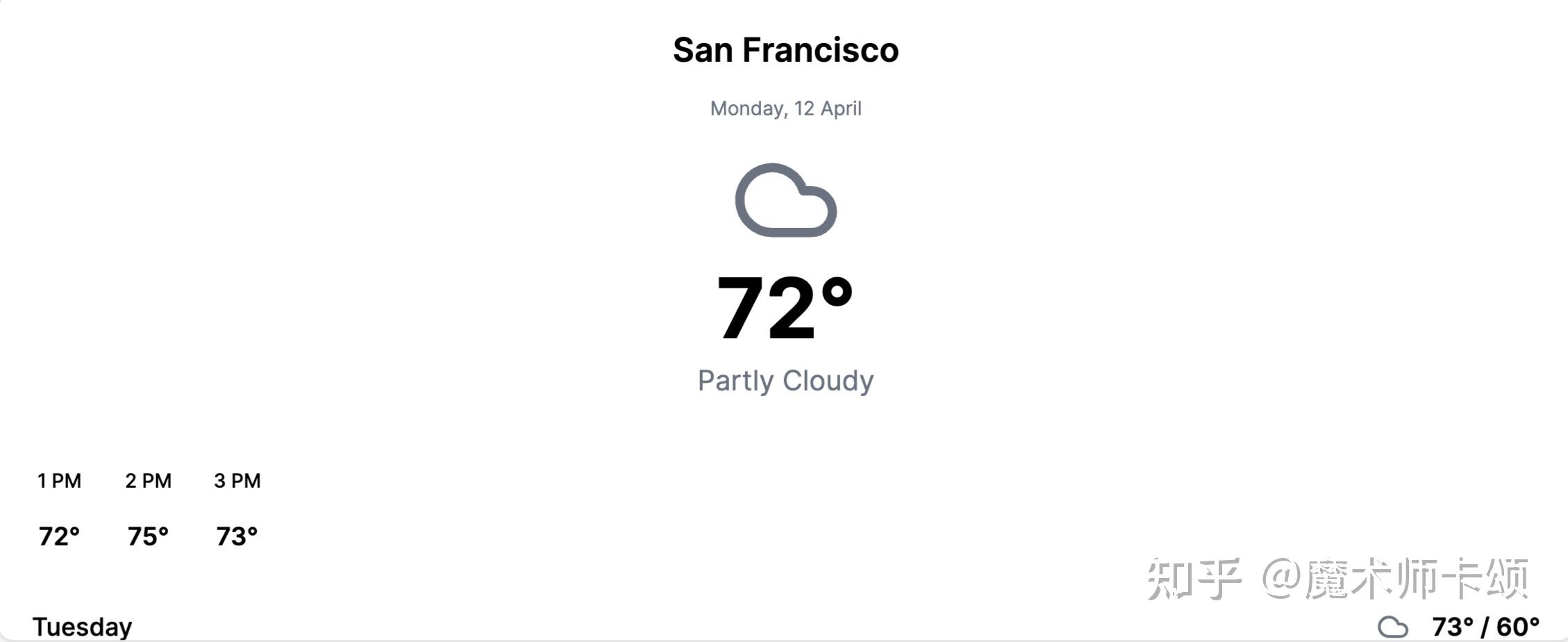
- 我们可以继续对不满意的地方提出修改意见,比如 「背景请使用渐变蓝色」 :
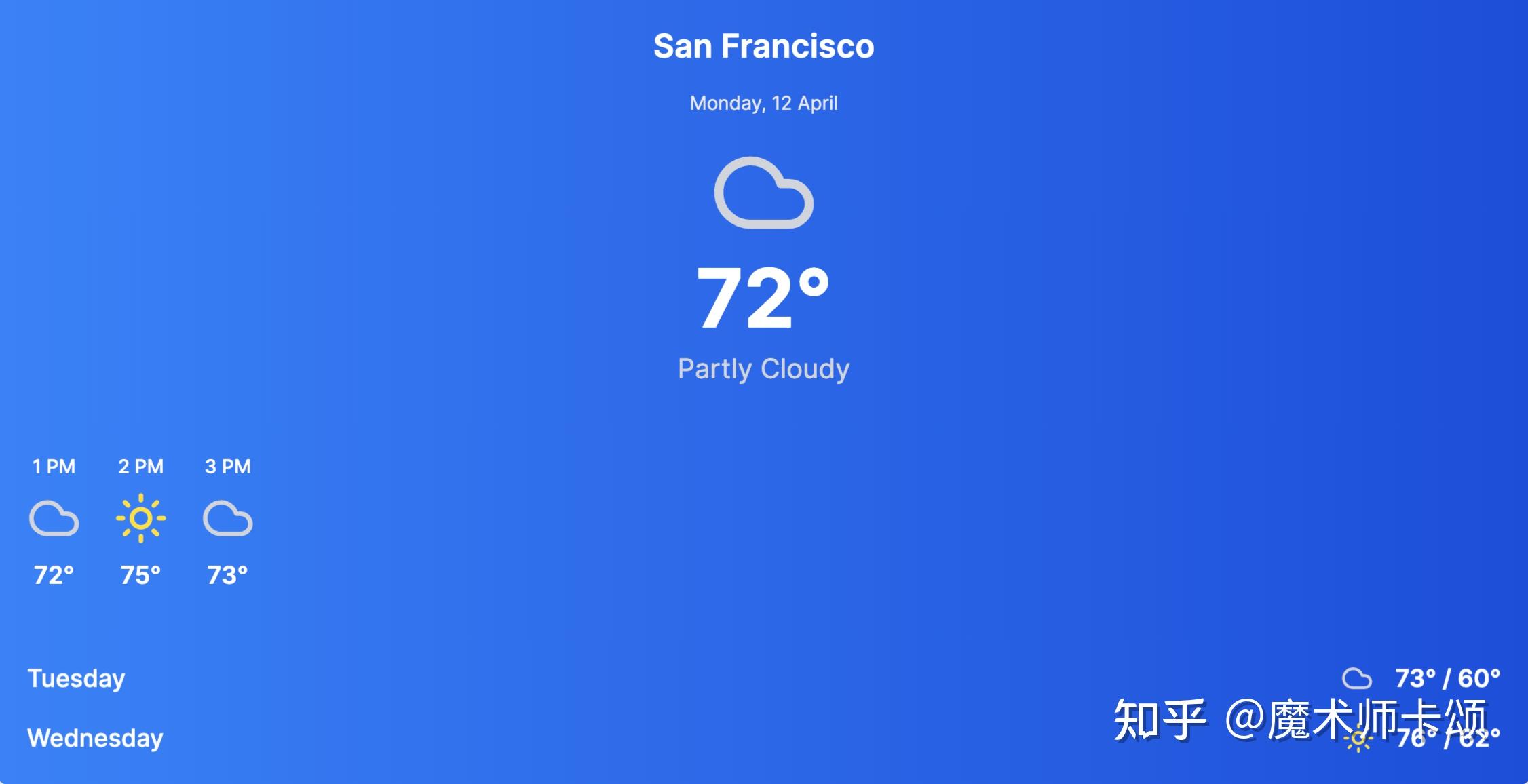
此时,会生成一个新的版本(这里是 v1)。具体来说,每个修改意见都会产生一个新的版本。当我们再提出 —— 「内容宽度为500px」 ,此时会产生 v2:
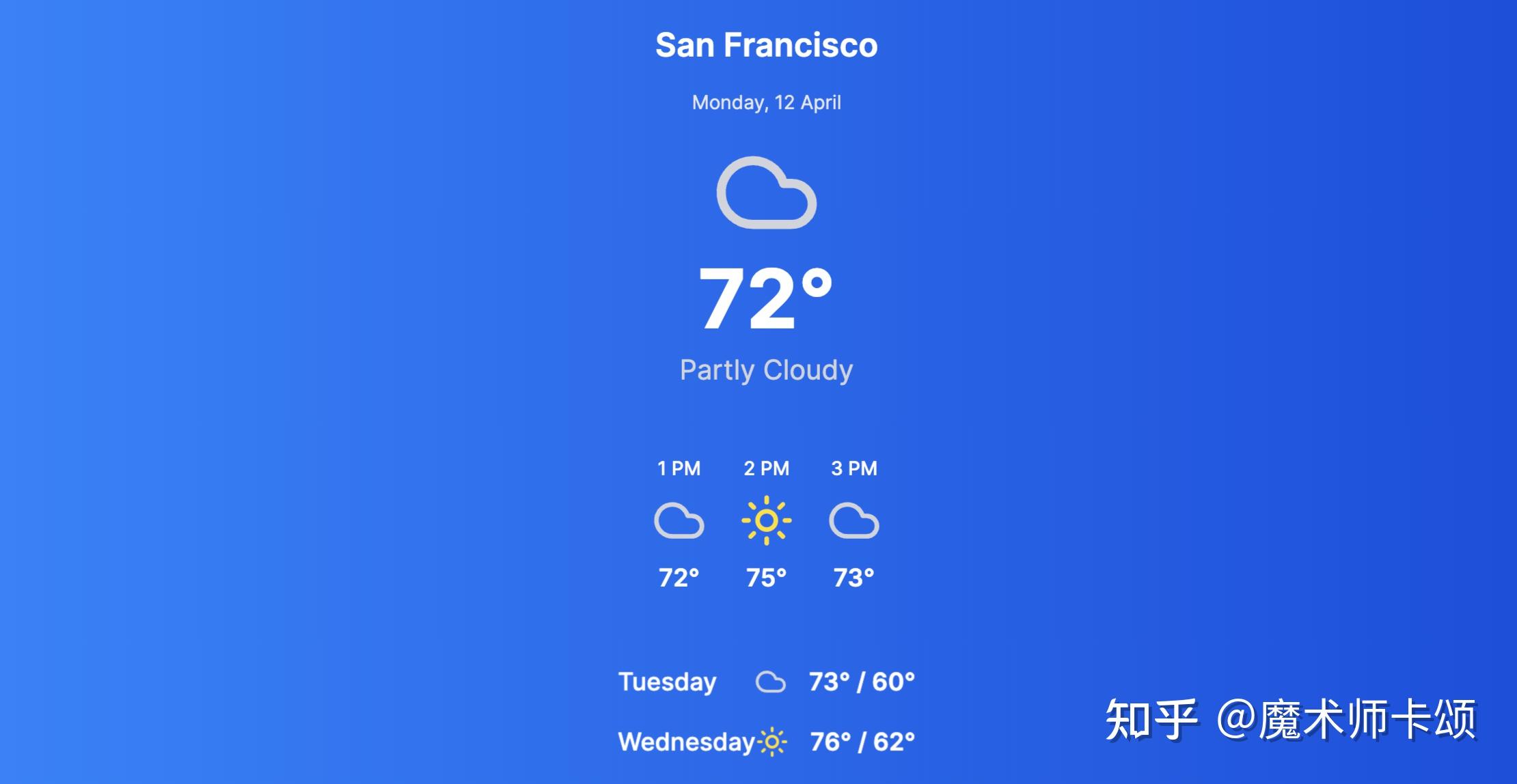
现在你明白这款产品为什么叫 v0 了吧?v0 指产品的最初版本,开发者可以基于 v0 不断迭代新的版本。而迭代的方式,就是不断提出新需求或修改意见。
有同学可能会问:我直接向 chatGPT 提需求不也能生成代码,v0 有啥优势?
v0 的优势主要体现在两点:
- 可以针对组件不同部分单独修改
- UI 与样式分离
让我们细细聊一下。
可以针对组件不同部分单独修改
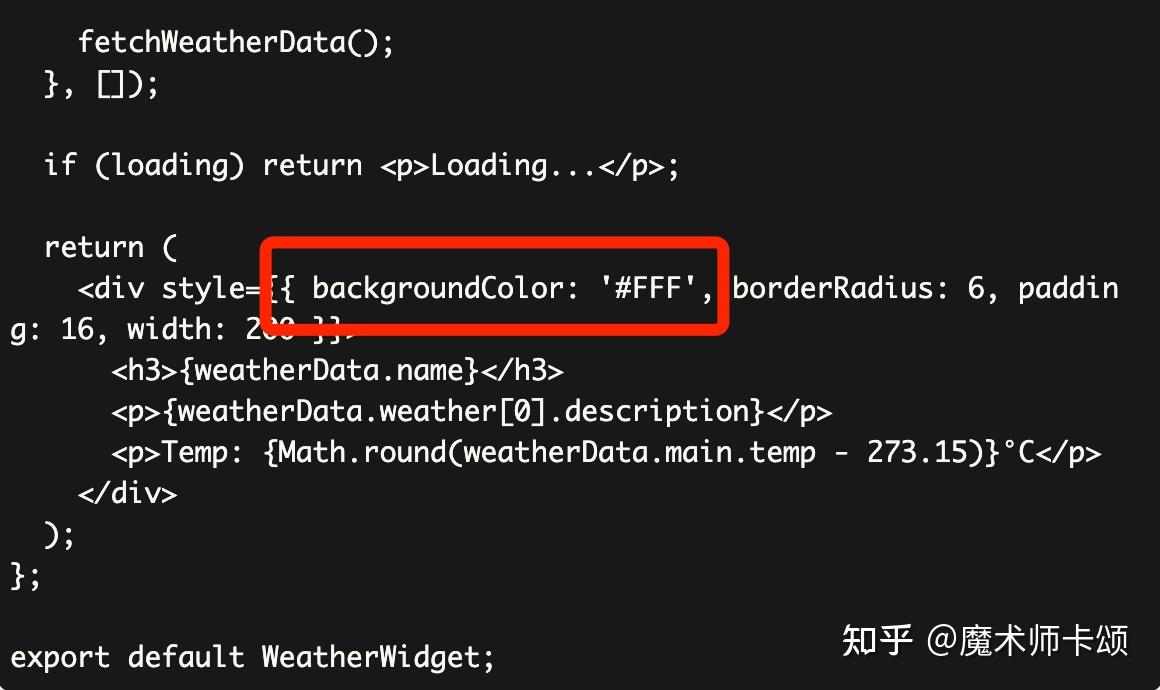
如果直接让 chatGPT 生成代码,那么他会生成一大段代码。比如,我让 chatGPT 生成上面提到的天气预报组件。下面截取了他返回代码的一部分,注意其中红框中组件背景色是白色:
现在,我继续提问: 「背景请使用渐变蓝色」 ,chatGPT 重新输出了组件代码,并把背景色改为渐变蓝色:
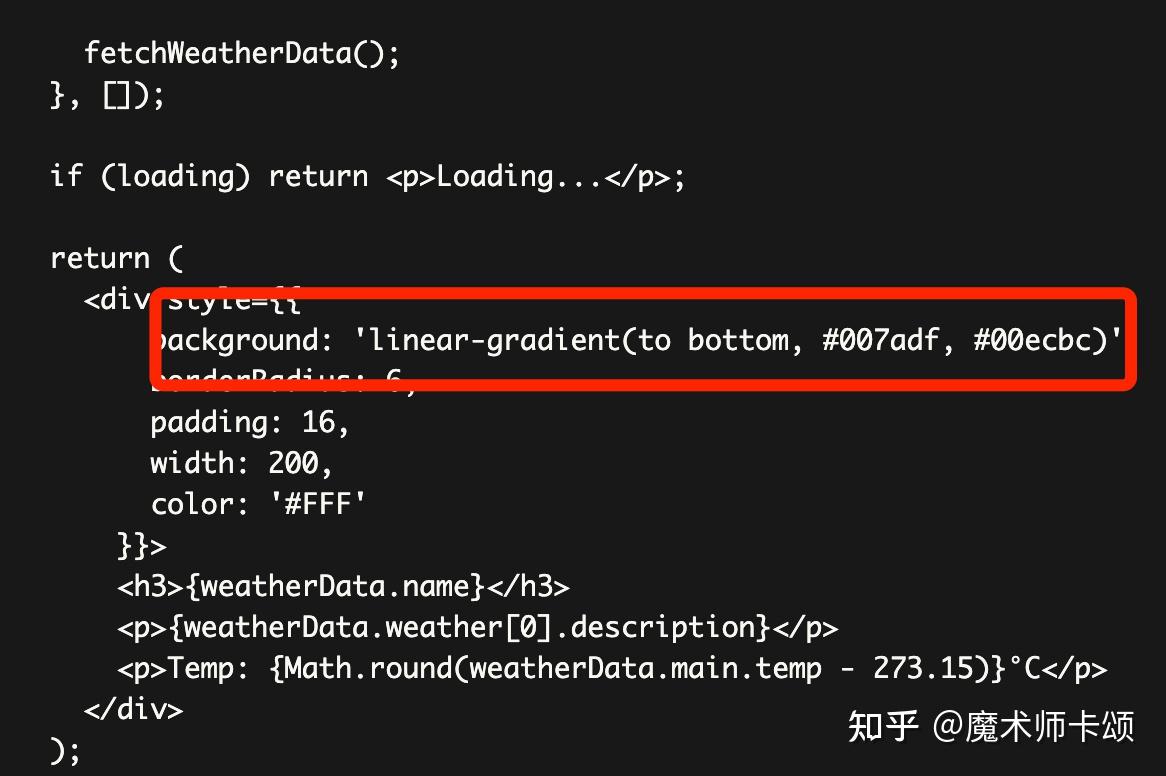
可以看到,每次提出修改意见,chatGPT 都得重新生成完整代码,比较低效。
那我只让 chatGPT 输出修改部分的代码呢?比如这样提问 —— 「内容宽度为 500px,只给出修改的代码」 。
他确实只输出了需要修改的代码:
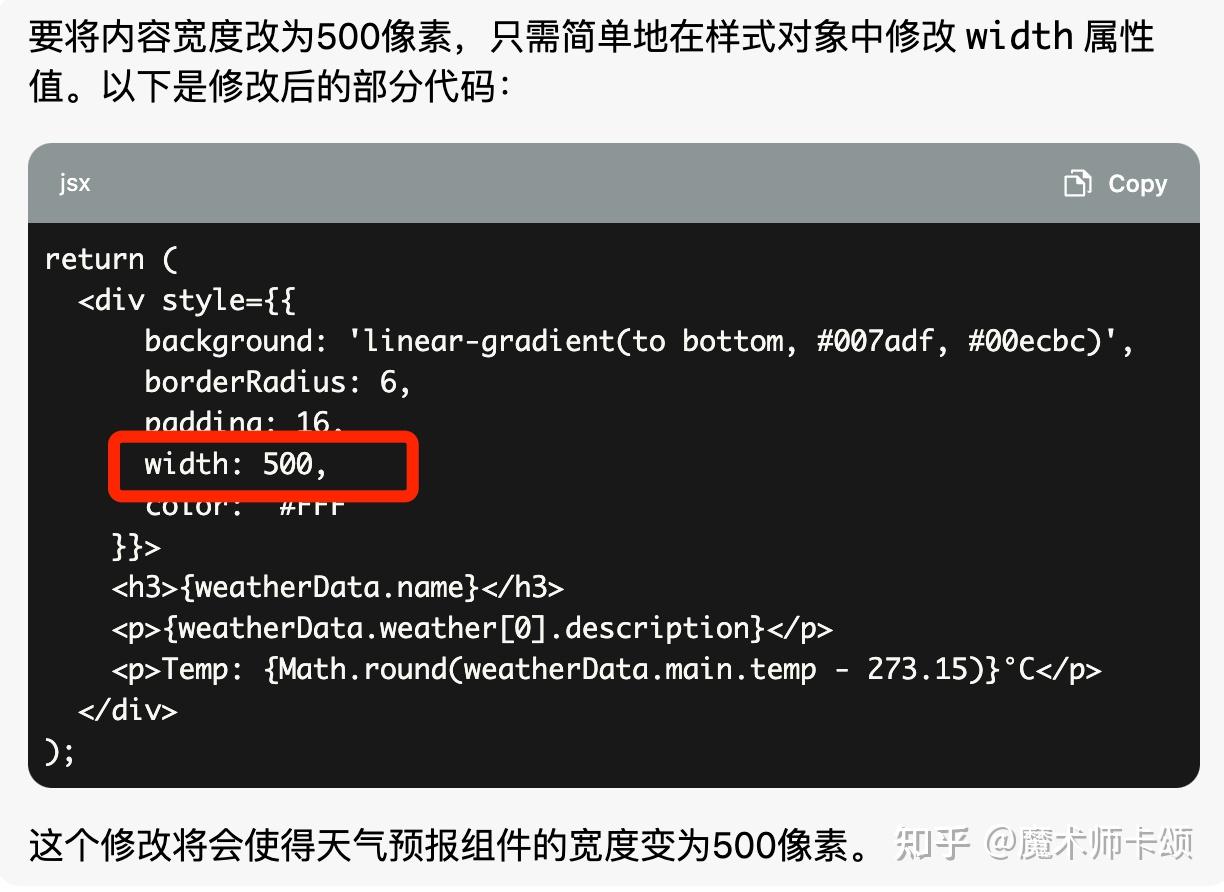
但这样也存在一个弊端 —— 当应用庞大时,需要让 chatGPT 知道我们想修改哪部分代码。
比如下面是个邮箱收集页面,现在我们希望将标题改为渐变色。当我们向 chatGPT 提到 「标题」 时,他能理解指的是邮箱收集页的标题。
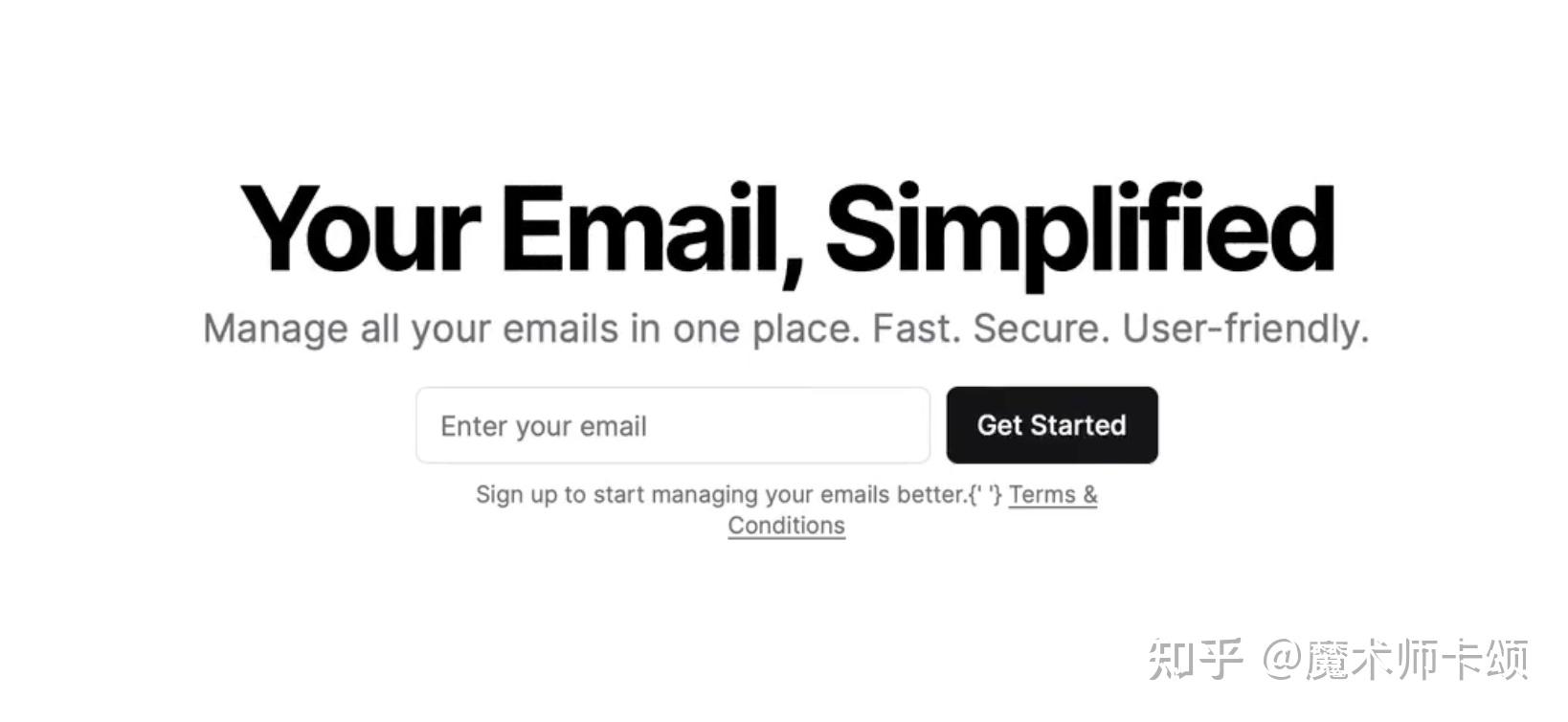
但当应用变得复杂,存在很多 「带标题的组件」 ,让 chatGPT 理解你的需求就得费一番功夫了。
使用 v0 就没有这方面困扰。我们可以对 v0 生成页面中的每个组件、每个元素单独提问。比如,对于上述 「将邮箱收集页标题改为渐变色」 的需求,首先用 v0 生成邮箱收集页。
现在我们希望将标题改为渐变色,只需要选择标题部分并提出 「增加一个渐变色」 :
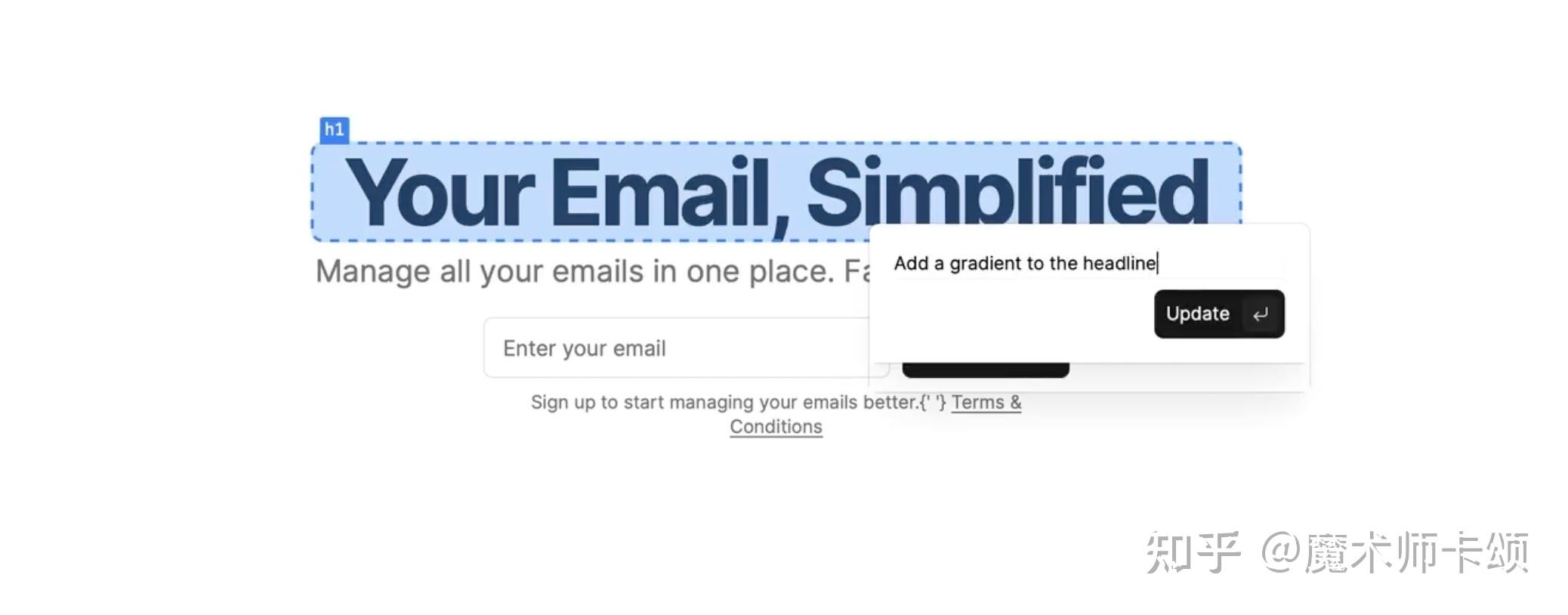
就能得到如下结果:

即使再复杂的页面,在提问时,v0 会将组件对应的上下文一并发送给大模型,模型能清楚知道要修改哪个组件。
UI 与样式分离
v0 生成的 React 组件代码中,样式与 UI 分别基于两个库:
- 样式:基于
TailwindCSS UI:基于 shadcn
样式部分
为什么生成代码的样式部分要使用 TailwindCSS 呢?
在我上一篇讲 TailwindCSS 的文章中我提到一个观点 —— 随着 AI 生成代码的普及,类似 TailwindCSS 这样的 「原子化 CSS」 会越来越普及。
这是因为,在有限的未来,大模型输出的 token 限制还会一直存在,而 「原子化 CSS」 相比 「语义化 CSS」 能用更少的字符表达更丰富的样式信息。
这里有两层意思,首先来看比较好理解的,对比下面两段代码:
「原子化 CSS」 的实现:
<div class="m-1"></div>
「语义化 CSS」 的实现:
<div class="container"></div>
.container {
margin: 0.25rem;
}
显然,从大模型的字符输出消耗来看, 「原子化 CSS」 能用更少字符表达同样的样式。
第二层意思, 「原子化 CSS」 (不管是 TailwindCSS 还是 UnoCSS)都是基于设计系统的上层封装。上述 m-1 的类名背后,并不仅仅是 margin: 0.25rem 的意思,而是与其他类名一起构成的设计系统。
当整个应用都是基于设计系统实现时,整体来看,达到同样的布局效果,也会更省大模型的字符输出消耗。
UI 部分
v0 的 UI 部分非常有意思,他基于 shadcn 这个“组件”库。
为什么要给 「组件」 打引号,因为 shadcn 与一般的组件库完全不同。
对于一般的组件库,我们先通过 npm 安装它,将它作为项目的依赖,再在项目中引入。
比如,下面是引入 antd 中 Calendar 组件的方式:
import { Calendar } from 'antd';
const App: React.FC = () => {
return <Calendar />;
};
下面是引入 shadcn 中 Calendar 组件的方式,对比看看有啥区别?
import { Calendar } from "@/components/ui/calendar"
const App: React.FC = () => {
return <Calendar />;
};
antd 中的 Calendar 来自于 antd 模块,而 shadcn 中的 Calendar 则来自于项目目录下的 components 目录。
这就是 shadcn 的理念 —— 0 依赖,按需复制粘贴代码。
简单来说,如果你想使用 shadcn 中的某个组件,不是通过 npm 安装 shadcn 这个包,再引入组件。而是直接复制该组件的代码到项目目录下(当然,整个复制过程是通过 cli 工具完成的)。
这么做相比于传统组件库,有两个显著优势:
- 组件逻辑想改就改,不用担心组件没暴露对应的
props
毕竟,整个组件的源代码我们都直接复制下来了,改个逻辑还不简单?
UI与样式分离
复制下来的组件只包含基础样式,开发者根据需要增加自定义样式。
总结
了解了 v0 能做什么,以及输出代码的组成后,我们可以得出结论 —— v0 是一款快速生成项目原型代码的 AI 工具。生成的原型代码中,UI 与样式分离,其中:
UI:基于shadcn- 样式:基于
TailwindCSS
UI 部分之所以基于 shadcn,显然是为了开发者导出代码后,可以方便的二次开发。
我们可以将 v0 当作一款应用场景更广的低代码工具,用于快速生成原型代码。从这个角度看,他对前端的影响还局限在提效工具上(而不是替代前端)。
与其担心 v0 会取代你的工作,不如担心隔壁悄悄使用 v0 的同事比你工作效率来的更高……
Double Brace Initialization should not be used
Java static code analysis: Double Brace Initialization should not be used
匿名内部类 内存泄漏
java
Why is this an issue?
Because Double Brace Initialization (DBI) creates an anonymous class with a reference to the instance of the owning object, its use can lead to memory leaks if the anonymous inner class is returned and held by other objects. Even when there’s no leak, DBI is so obscure that it’s bound to confuse most maintainers.
For collections, use Arrays.asList instead, or explicitly add each item directly to the collection.
1. You’re creating way too many anonymous classes
Each time you use double brace initialisation a new class is made. E.g. this example:
Map source = new HashMap(){{
put("firstName", "John");
put("lastName", "Smith");
put("organizations", new HashMap(){{
put("0", new HashMap(){{
put("id", "1234");
}});
put("abc", new HashMap(){{
put("id", "5678");
}});
}});
}};… will produce these classes:
Test$1$1$1.class
Test$1$1$2.class
Test$1$1.class
Test$1.class
Test.classThat’s quite a bit of overhead for your classloader - for nothing! Of course it won’t take much initialisation time if you do it once. But if you do this 20’000 times throughout your enterprise application… all that heap memory just for a bit of “syntax sugar”?
2. You’re potentially creating a memory leak!
If you take the above code and return that map from a method, callers of that method might be unsuspectingly holding on to very heavy resources that cannot be garbage collected. Consider the following example:
public class ReallyHeavyObject {
// Just to illustrate…
private int[] tonsOfValues;
private Resource[] tonsOfResources;
// This method almost does nothing
public Map quickHarmlessMethod() {
Map source = new HashMap(){{
put("firstName", "John");
put("lastName", "Smith");
put("organizations", new HashMap(){{
put("0", new HashMap(){{
put("id", "1234");
}});
put("abc", new HashMap(){{
put("id", "5678");
}});
}});
}};
return source;
}
}The returned Map will now contain a reference to the enclosing instance of ReallyHeavyObject. You probably don’t want to risk that:
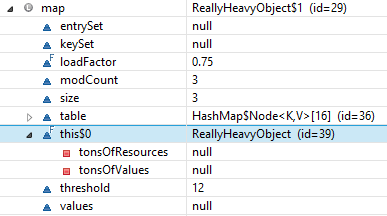
Example
Noncompliant code example
Map source = new HashMap(){{ // Noncompliant
put("firstName", "John");
put("lastName", "Smith");
}};
Compliant solution
Map source = new HashMap();
// …
source.put("firstName", "John");
source.put("lastName", "Smith");
// …