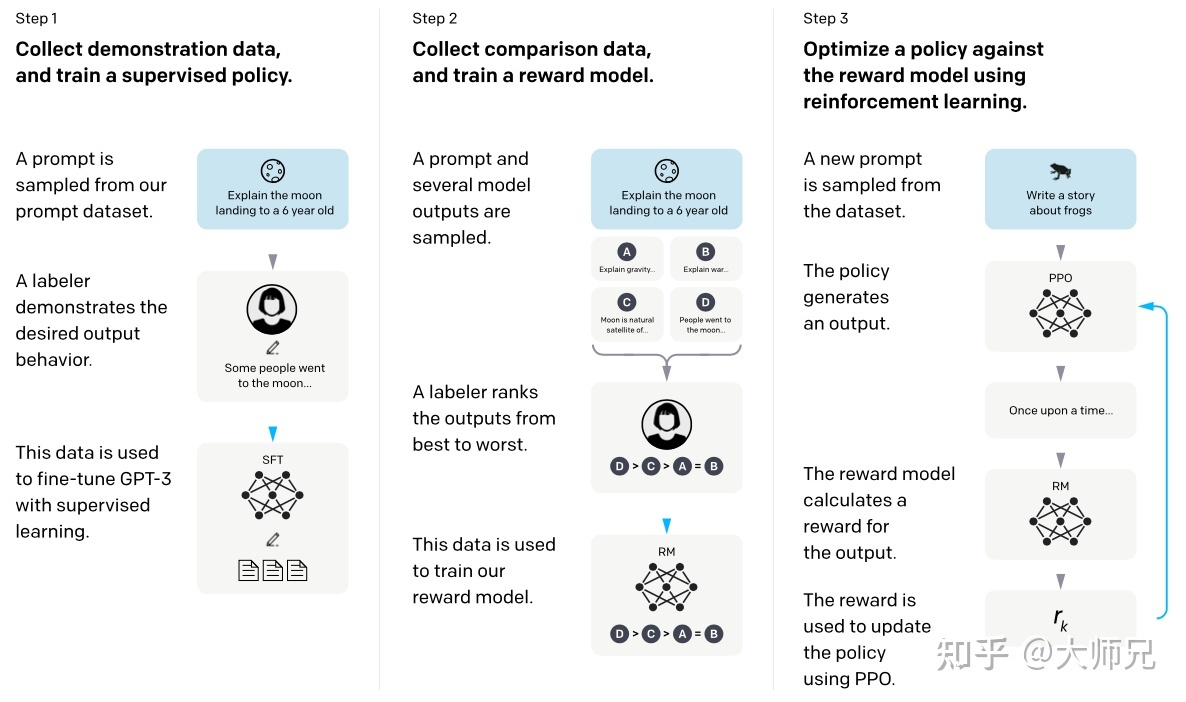
ChatGPT 的训练可以分成 3 步,其中第 2 步和第 3 步是的奖励模型和强化学习的 SFT 模型可以反复迭代优化。
- 根据采集的 SFT 数据集对 GPT-3 进行 有监督微调 (Supervised FineTune,SFT);
- 收集人工标注的对比数据,训练 奖励模型 (Reword Model,RM);
- 使用 RM 作为强化学习的优化目标,利用 强化学习模型 (Proximal Policy Optimization, PPO) 算法微调 SFT 模型。
ChatGPT 的训练可以分成 3 步,其中第 2 步和第 3 步是的奖励模型和强化学习的 SFT 模型可以反复迭代优化。