const currentPage = dv.current().file;
const dailyPages = dv.pages('"0-Daily"').sort(k=>k.file.name, "asc");
const currentPageName = currentPage.name;
const index = dailyPages.findIndex((e) => {return e.file.name === currentPageName});
if (index < 1) {
dv.table(["File", "Created", "Size"],[]);
} else {
const lastIndex = index - 1;
const lastPage = dailyPages[lastIndex].file;
const allPages = dv.pages().values;
const searchPages = [];
const lastTime = dv.parse(lastPage.name);
const currentTime = dv.parse(currentPage.name);
for (let page of allPages) {
const pageFile = page.file;
if (pageFile.cday > lastTime && pageFile.cday <= currentTime) {
searchPages.push(pageFile);
}
}
dv.table(["File", "Created", "Size"], searchPages.sort((a, b) => a.ctime > b.ctime ? 1 : -1).map(b => [b.link, b.ctime, b.size]));
}
java 反序列化漏洞检测
白盒工具检测
白盒代码审计工具,可通过在 调用链 中查找是否有发序列化的操作:
调用链的入口不同框架是不同的,例如在2例子中调用链的入口为 spring-boot 的_controller_。
调用链中一旦发现有发序列化操作ObjectInputStream.readObject()则该接口存在序列化操作
但仅仅依靠以上信息不足以判断是否存在漏洞,还需要判断代码中是否有存在*执行链**的三方依赖。在java中,一般通过分析 pox.xml build.gradle 文件来分析是否包含有漏洞的组件。
黑盒漏洞扫描器检测
web漏洞扫描器检测原理和白盒工具不一样。
首先漏洞扫描器要解决的是识别出反序列化的请求,在这里需要注意的是web漏洞扫描是无法通过爬虫方式直接发现反序列化接口的,因此往往需要配合其他web漏洞扫描器的组件(例如代理组件)来识别反序列化接口,如下图所示
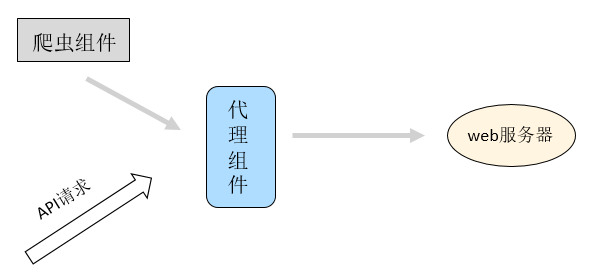
如今web漏洞扫描器都提供了代理组件来发现应用的http请求,爬虫组件可通过前台页面触发请求进入代理组件;但在API场景下,还是需要测试人员进行API调用该操作才能够产生http请求数据。
在截获到http请求数据后,代理组件可以通过两种方式判断一个请求是否是序列化请求:
通过http请求的Content-Type,具体来说ContentType: application/x-java-serialized-object 是序列化请求的请求头
检查请求数据的开头是否是 0xaced,有时候序列化请求不存在正确的content-type,此时需要根据数据来判断是否是序列化请求
在确定一个接口是序列化接口的时候会漏洞扫描器会发送探测payload判断接口是否有反序列化漏洞,这里的攻击payload类似于1.2节中使用的ysoserial(https://github.com/frohoff/ysoserial)工具,由于绝大多数情况下不可能看到回显(http返回数据没有攻击执行结果),因此只能进行 盲注 ,即发送 sleep 10 这样的命令,根据响应时间判断是否有漏洞。