该课程来之《数据密集型应用系统设计》的作者 Martin Kleppmann 分享的 《Distributed Systems》课程,共 8 章,我觉得非常有价值,因此翻译成中文版,本文为第三章 Time, clocks, and ordering of events。
让我们从一个谜题开始,它将在本讲的后面得到解决。

在本讲中,我们将讨论分布式系统中的时间概念。我们已经看到,我们对时间的假设构成了分布式算法所依赖的系统模型的一个关键部分。例如,基于超时的故障检测器需要测量时间来确定超时已经过时。操作系统广泛地依赖于计时器和时间度量来调度任务、跟踪 CPU 的使用情况以及许多其他用途。应用程序通常希望记录事件发生的时间和日期:例如,当在分布式系统中调试一个错误时,时间戳对调试很有帮助, 因为它们允许我们在不同的节点上重建大约在同一时间发生的事情。所有这些都需要或多或少精确的时间测量。

3.1 物理时钟
物理时钟以秒为单位测量时间。它们包括基于钟摆或类似机制的模拟/机械时钟,以及基于振动的石英晶体上数字时钟。大多数手表、电脑和手机、显示时间的微波炉以及许多其他日常用品中都有石英时钟。物理时钟有时也被称为挂钟,即使它们不需要连接在真正的墙上。

石英时钟很便宜,但它们并不完全准确。由于制造上的缺陷,有些时钟运行得比其他的稍快一些。此外, 振荡频率随温度而变化。典型的石英时钟在室温下被调得相当稳定,但明显较高或较低的温度会使时钟变慢。时钟运行得快或慢的速度被称为 漂移(drift)。
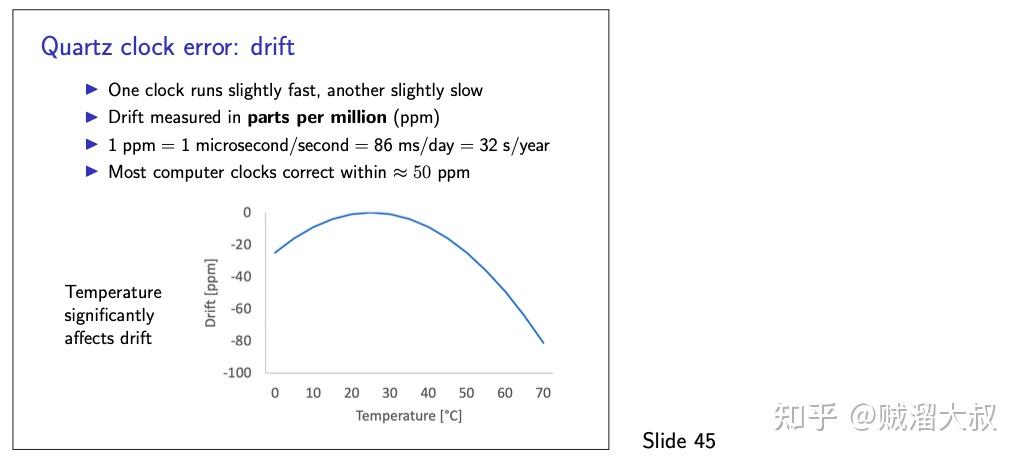
当需要更高的精度时,就会使用原子钟。这些时钟是基于某些原子的量子力学特性,如铯或铷。事实上,在国际单位制(International System of Units, SI)中,一秒的时间单位被认为恰好是铯-133 原子的特定共振频率的 9,192,631,770 个周期。

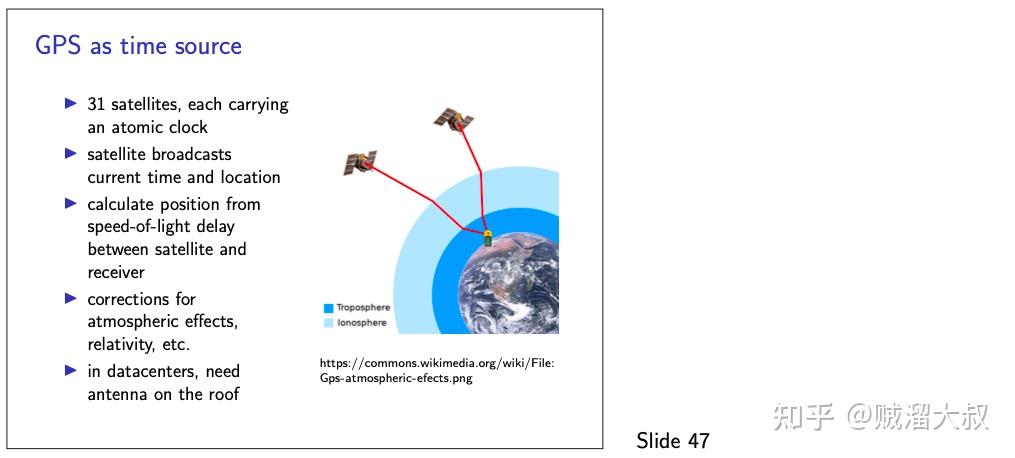
另一种获取时间的高精度方法是依赖于 GPS 卫星定位系统,或类似的系统,如伽利略(Galileo)或格洛纳斯(GLONASS)。这些系统的工作原理是有几颗卫星绕地球运行,并以非常高的分辨率广播当前的时间。接收器测量每颗卫星的信号到达它们所需的时间,并使用它来计算它们与每颗卫星的距离,从而计算它们的位置。通过将 GPS 接收器与计算机连接,只要接收器能够从卫星上获得清晰的信号,就可以获得精确到微秒以内的时钟。在一个数据中心中,通常会有太多的电磁干扰而无法获得一个良好的信号,所以一个 GPS 接收器需要在数据中心大楼的屋顶上安装一个天线。
基于原子钟(国际原子时间,International Atomic Time, TAI)的时间测量系统工作得很好,但它与我们日出日落时间的日常时间感知无关。 地球绕着它自己的轴自转一次并不需要铯-133 的共振频率的 24×60×60×9,192,631,770 个周期。事实上,地球的自转速度甚至都不是恒定的:由于潮汐、地震、冰川融化和一些无法解释的因素。我们现在有了一个问题:我们有两个不同的时间问题 —— 一个基于量子力学, 另一个基于天文学——这两个定义并不精确匹配。
解决方案是协调通用时间 (Coordinated Universal Time,UTC),它是基于原子时间的,但也包括对地球自转变化的修正。在日常生活中, 我们使用我们当地的时区,这是 UTC 的一部分。
英国当地的时区在冬季被称为格林威治平均时间 (Greenwich Mean Time,GMT),在夏季被称为英国夏季时间 (British Summer Time,BST),格林威治时间被认为等于 UTC,英国标准时间被认为为 UTC+1 小时。令人困惑的是,术语格林威治平均时间最初是用来指格林威治子午线上的平均太阳时间。它曾经是用天文学来定义的,而现在它是用原子钟来定义的。今天,术语_UT1_ 被用来指经度 0°处的平均太阳时间。
UTC 和 TAI 之间的区别在于,UTC 包括 闰秒(leap seconds),并根据需要添加闰秒,以保持 UTC 与地球的自转大致同步。

由于闰秒,这并不会一个小时总是有 3600 秒和一天总是有 86,400 秒。在 UTC 的时间表上,一天的闰秒长度可以是 86399 秒、86400 秒或 86401 秒。这使得需要处理日期和时间的软件变得复杂。

在计算机中,时间戳是对特定时间点的表示。通常使用两种时间戳表示:Unix 时间(Unix time)和 ISO 8601。对于 Unix 时间,0对应于任意选择的1970年1月1日的日期,被称为 纪元(epoch)。这里也有一些微小的变化:例如,Java 的 System.currentTimeMillis() 类似于 Unix 时间,但是使用的是毫秒而不是秒。
正确地说,使用时间戳的软件需要了解闰秒。例如,如果你想计算在两个时间戳之间经过了多少秒, 那么你需要知道在这两个日期之间插入了多少闰秒。对于超过 6 个月以后的日期,这是不可能知道的,因为地球的自转还没有发生!
软件中最常见的方法是干脆忽略闰秒,假装它们不存在,然后希望这个问题以某种方式消失。Unix 时间戳和 POSIX 标准都采用了这种标准。对于只需要粗粒度计时的软件(例如四舍五入到最近的一天),这是正确的,因为几秒钟的偏差并不重要。
然而,操作系统和分布式系统通常确实依赖于高精度的时间戳来精确地测量时间,其中一秒的偏差是非常明显的。在这种设置下,忽略闰秒可能是很危险的。例如,假设您有一个 Java 程序,它在一个正闰秒内两次调用 System.currentTimeMillis () ,间隔 500ms (即当时钟显示为 23:59:60)。这两个时间戳之间的相差是什么?它不可能是 500,因为当前的时间 currentTimeMillis() 时钟不考虑闰秒。时钟停止了吗,所以两个时间戳之间的差是零?或者差异甚至是负的,所以时钟倒退了一小会儿?本文档不提及这个问题。(最好的解决方案可能是使用单调时钟 monotonic clock ,我们将在幻灯片 58 中介绍)
2012 年 6 月 30 日的闰秒处理不当,是导致当天许多服务同时出现故障的原因(幻灯片 42)。由于 Linux 内核中的一个 bug,闰秒在运行多线程进程时触发活锁条件的可能性很高[Allen, 2013, Minar, 2012]。即使是重新启动也不会解决这个问题,但是设置系统时钟会重置内核中的坏状态。
今天,一些软件显式地处理闰秒,而其他程序则继续忽略它们。今天广泛使用的一个实用的解决方案是, 当正闰秒发生时,不是在 23:59:59 和 00:00:00 之间插入,而是在该时间之前和之后的几个小时内,通过故意放慢时钟(或在负闰秒的情况下加速),将额外的闰秒分散开来。这种方法被称为涂抹(smearing)闰秒,它并非没有问题。然而,这是一个实用的替代方案,使所有软件都能感知并支持闰秒,这很可能是不可行的。
练习 6. 描述一些由涂抹闰秒可能产生的问题。
3.2 时钟同步和单调时钟

原子钟过于昂贵和笨重,无法植入每台电脑和手机上,所以使用石英时钟。由于这些时钟会漂移,它们需要不时地进行调整,这通常是使用 网络时间协议(Network Time Protocol, NTP) 来完成的。所有的主流操作系统都内置了 NTP 客户端。

网络上的时间同步由于不可预测的延迟而产生了干扰。 正如在幻灯片 36 上所讨论的,网络延迟和节点的处理速度都可能有很大的不同。为了减少随机变化的影响,NTP 采取了几个时间测量的样本,并应用统计信息来消除异常值。
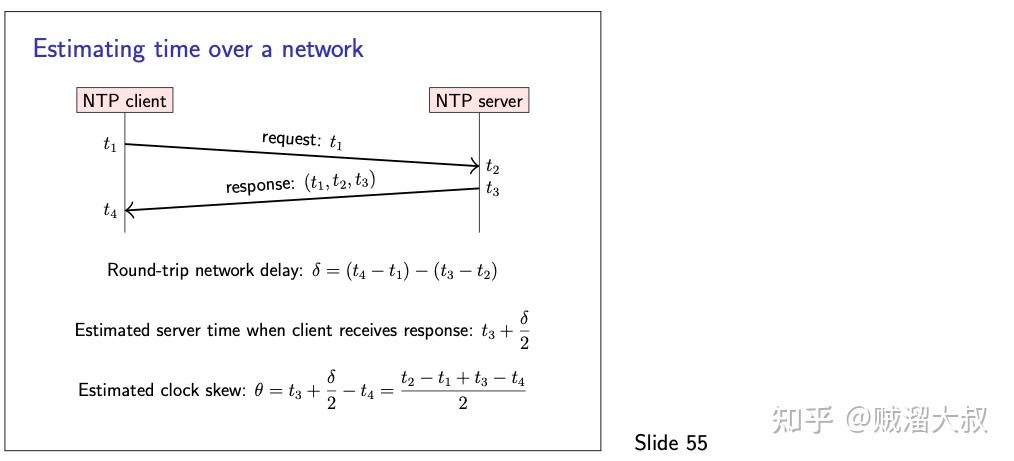
幻灯片 55 显示了 NTP 如何估计客户端和服务器之间的时钟偏差。当客户端发送一个请求消息时,它会根据客户端的时钟包含当前的时间戳 t1。当服务器接收到请求时,在处理之前,服务器根据服务器的时钟记录当前时间戳 t2。当服务器发送响应时,它会回显请求中的值 t1,并在响应中包含服务器的收据时间戳 t2 和服务器的响应时间戳 t3。最后,当客户端接收到响应时,它会根据客户端的时钟记录当前的时间戳 t4。
我们可以通过从客户端的角度计算往返时间(t4 - t1),并减去在服务器上的处理时间(t3 - t2)来确定消息在网络上传输所花费的时间。然后,我们估计单向网络延迟为总网络延迟的一半。因此,当响应到达客户端时,我们可以估计服务器的时钟将移动到 t3 加上单向网络延迟。然后我们从估计的服务器时间中减去客户端的当前时间 t4,得到两个时钟之间的估计偏差。
这种估算取决于两个方向的网络延迟大致相同的假设。如果延迟主要由客户端和服务器之间的地理距离决定,那么这个假设可能是正确的。然而,如果网络中的排队时间是延迟中的一个重要因素(e.g. 如果一个节点的网络链路负载很重,而另一个节点的链路有足够的空闲容量),那么请求和响应延迟之间可能会有很大的差异。不幸的是,大多数网络不会给节点任何特定数据包所经历的实际延迟的指示。
练习 7. 假设两个节点都正确地遵循协议,NTP 客户端对某一特定服务器的偏差估算的最大可能误差是多少?
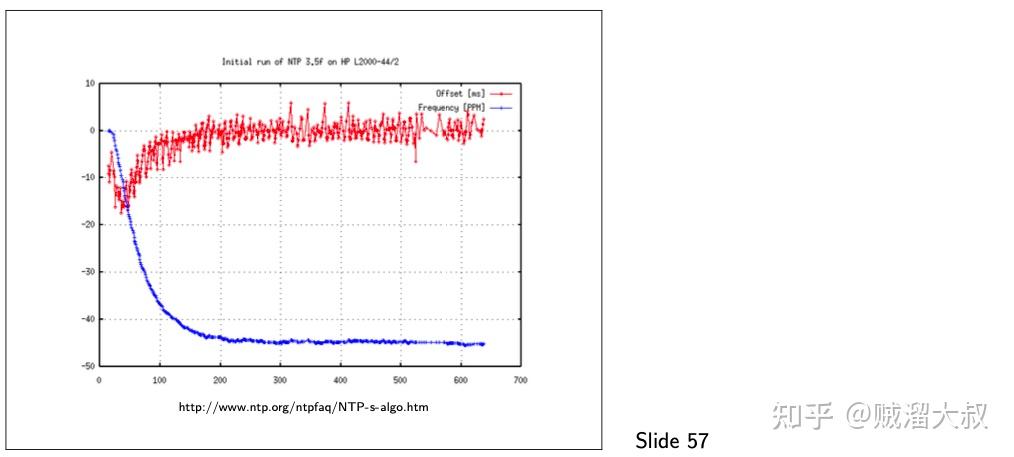
一旦 NTP 估计了客户端和服务器之间的时钟偏差,下一步就是调整客户端的时钟,使其与服务器保持一致。为此所用的方法取决于偏差的大小。客户端通过将时钟速度调整到运行速度稍快或稍慢,轻轻地纠正微小偏差,这在几分钟的过程中逐渐减少偏差。这个过程叫做旋转(slewing)时钟。
幻灯片 57 显示了一个旋转的例子,在这个例子,客户端的时钟频率收敛到与服务器相同的速率,使两者保持在几毫秒内的同步。当然,在特定系统中实现的精确度取决于客户端和服务器之间网络的时间属性。
但是,如果偏差较大,则旋转偏差将花费太长时间,因此 NTP 客户端会根据服务器时间戳强制将其时钟设置为估算的正确时间。这就是所谓的步进时钟(stepping the clock)。任何监视客户端时钟的应用程序都会看到时间突然向前或向后跳跃。
最后,如果偏差非常大(默认情况下,超过 15 分钟),NTP 客户机可能会认为出现了问题,并拒绝调整时钟,将问题留给用户或操作员来纠正。出于这个原因,任何依赖于时钟同步的系统都需要仔细监控时钟偏差:仅仅因为一个节点正在运行 NTP,这并不能保证它的运行时钟将是正确的,因为它可能会陷入恐慌(painc)状态,拒绝调整时钟。

事实上,时钟可能是由于 NTP 步进(stepped),例如突然向前或向后移动,对任何需要衡量运行时间的软件都有重要的影响。幻灯片 58 显示了一个 Java 的示例,我们想要测量 doSomething() 的函数的运行时间。Java 有两个核心函数,用于从操作系统的本地时钟获取当前时戳:currentTimeMillis() 和 nanoTime()。除了不同的精度(毫秒与纳秒)外,两者之间的关键差异是它们在面对 NTP 或其他来源的时钟调整时的表现。
currentTimeMillis()是一个日历时钟(time-of-day clock) (也称为实时时钟 real-time clock),它返回自一个固定参考点(在本例中是 1970 年 1 月 1 日的 Unix 纪元 epoch)以来所经过的时间。当 NTP 客户端步进本地时钟时,可能会出现日历时钟跳转。因此,如果您使用这样的时钟来测量运行时间,那么结束时间戳和开始时间戳之间的结果差异可能会远远大于实际运行时间(如果时钟向前走),甚至可能是负的(如果时钟向后走)。因此,这种类型的时钟不适合测量经过的时间。
另一方面,nanoTime()是一个单调时钟,不受 NTP 步进的影响:它仍然计算已经过去的秒数,但它总是向前移动。 只是它前进的速率可以通过 NTP 旋转来调整。这使得一个单调的时钟在测量所经过的时间时更加稳健。缺点是,来之单调时钟的时间戳本身没有意义: 它测量自某个任意参考点以来的时间,例如自计算机启动以来的时间。当使用单调时钟时,只有来自同一节点的两个时间戳之间的差异是有意义的。比较不同节点之间的单调时钟时间戳是没有意义的。

大多数操作系统和编程语言都提供了一个的日历时钟(time-of-day clock)和一个单调时钟(monotonic clock),因为两者具有不同的用途。

3.3 因果关系和 happens-before
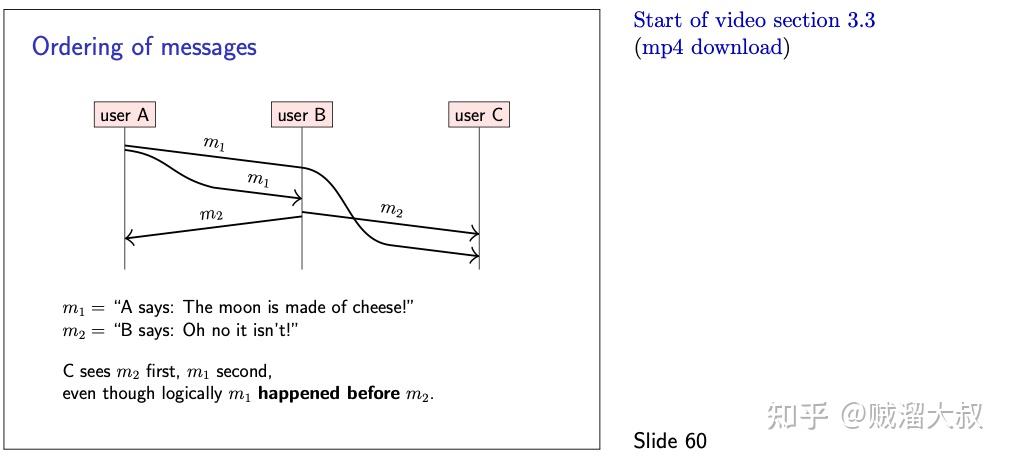
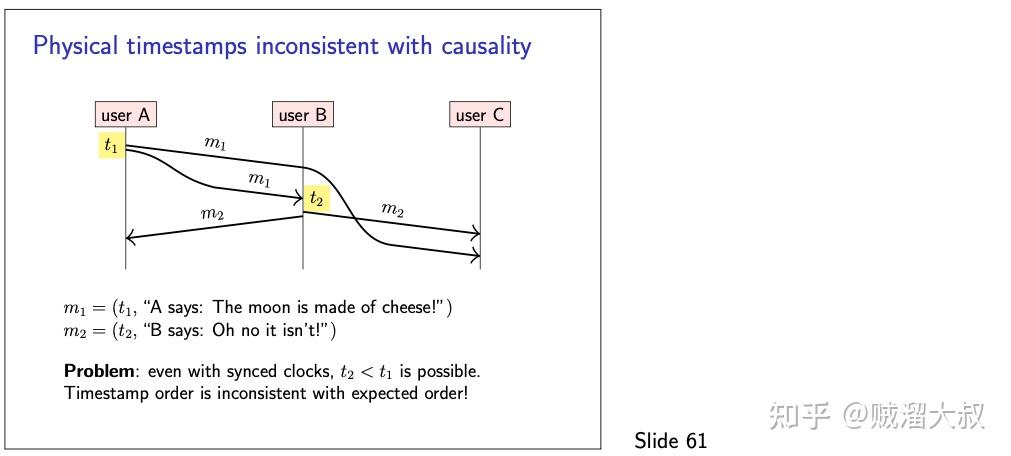
现在,我们将继续讨论分布式系统中的事件排序问题,这与时间的概念密切相关。考虑幻灯片 60 上的场景,在这个场景中,用户 a 发出一条语句 m1,并将其作为消息发送给另外两个用户 b 和 c。在收到 m1 时,用户 b 通过向另外两个用户 a 和 c 发送一个答复 m2 作为响应。然而,即使我们假设网络链路是可靠的,它们也允许重排序(幻灯片 33),因此如果 m1 在网络中稍微延迟,c 可能会在 m1 之前收到 m2。
从 c 的角度来看,结果是令人困惑的: c 先看到回复,然后看到回复的消息。看起来似乎 b 能够预见未来,甚至在 a 发表声明之前就预测到 a 的声明。在现实生活中,这种口语语言的重排序是不会发生的,所以我们直觉上也不希望它发生在计算机系统中。
作为一个更具技术性的例子,可以将 m1 视为在数据库中创建对象的指令,将 m2 视为更新同一对象的指令。如果一个节点在 m1 之前处理 m2,它将首先尝试更新一个不存在的对象,然后创建一个不会随后更新的对象。数据库指令只有在 m1 在 m2 之前被处理时才有意义。
c 如何确定消息的正确顺序?单调时钟无法工作,因为它的时间戳不能跨节点进行比较。第一种尝试可能是在用户想要发送消息时从日历时钟获取时间戳,并将该时间戳附加到消息。在这种情况下,我们可以合理地预期 m2 的时间戳要晚于 m1,因为 m2 是对 m1 的响应,所以 m2 一定发生在 m1之后。
不幸的是,在部分同步系统模型中,这并不可靠。由 NTP 和类似的协议执行的时钟同步总是对两个时钟之间的精确偏差留下一些的不确定性,特别是当两个方向的网络延迟是不对称时。因此我们不能排除以下情况:a 根据 a 的时钟发送带有时间戳 t1 的 m1。当 b 接收到 m1 时,根据 b 的时钟的时间戳是 t2,其中 t2 < t1,因为 a 的时钟稍早于 b 的时钟。因此,如果我们根据日历时钟的时间戳对消息进行排序,我们可能再次以错误的顺序结束。
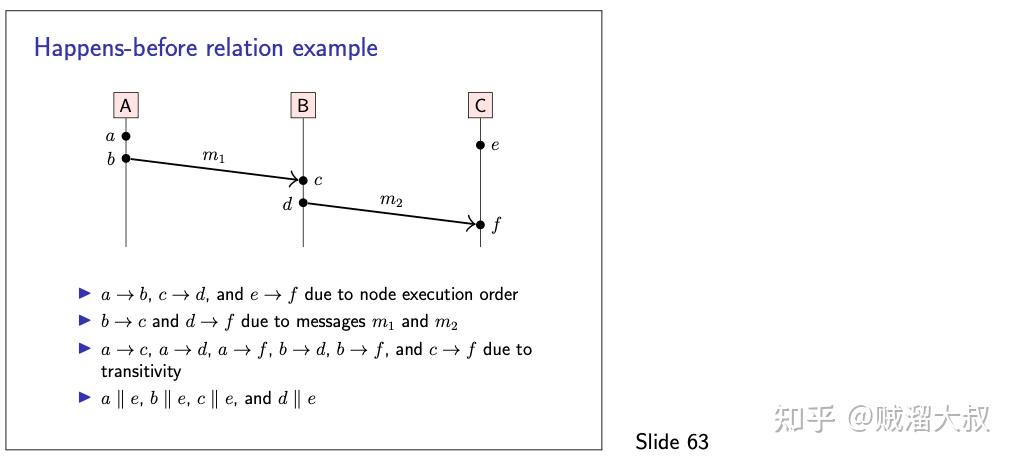
在这种情况下,为了形式化我们所说的“正确的”顺序,我们使用幻灯片 62 中定义的 happens-before 关系。该定义假设每个节点只有一个执行线程,因此对于一个节点的任意两个执行步骤,可以清楚地知道哪一个先发生。更正式地说,我们假设在同一节点上发生的事件有严格的总顺序。一个多线程进程可以通过使用单独的节点来表示每个线程来建模。
然后,我们来扩展跨节点之间这个顺序,通过定义在接收相同消息之前发送消息。(换句话说,我们排除了时空旅行可能性:不可能接收到尚未发送的消息)。为了方便起见,我们假定发送的每个消息都是唯一的,因此当接收到消息时,我们总是清楚地知道消息在何时何地发送的。在实践中,可能存在重复的消息,但我们可以使它们唯一,例如,通过在每条消息中包括发送者节点的 ID 和序列号。
最后,我们采用传递闭包,其结果是 happens-before 关系。这是一个偏序(partial order),这意味着对于某些事件 a 和 b,有可能 a 不在 b 之前发生,b 也不在 a 之前发生。在这种情况下,我们称 a 和 b 为并发的。注意,这里的“并发”并不是字面上的“同时”,而是 a 和 b 是独立的,没有从一个消息到另一个消息的顺序。

练习 8. 如果关系 R 是非自反的(irreflexive),它是严格的偏序
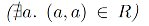
和传递的
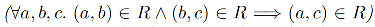
(这两个条件也暗示它 R 不对称,即
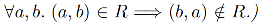
。证明事前 happen-before 关系是严格的偏序。你可以假设任意两个节点之间的距离不为零,以及信息传播速度不能超过光速的物理原理。
练习 9. 证明对于任意两个事件 a 和 b,以下三个陈述中必须有一个是正确的: a → b, or b → a, or a || b。
happens-before 关系是分布式系统中因果关系的一种推理方式。因果关系考虑的是信息是否可能从一个事件流向另一个事件,因此一个事件是否可能影响另一个事件。在第 60 张幻灯片的例子中,m2(”Oh no,它不是!”)是对 m1(“月亮是奶酪做的!”)的回复,因此 m1 影响了 m2。一个事件是否真的“导致”了另一个事件,这是一个我们现在不需要回答的哲学问题;对于我们的目的来说,重要的是 m2 的发送方在发送 m2 时已经收到了 m1。
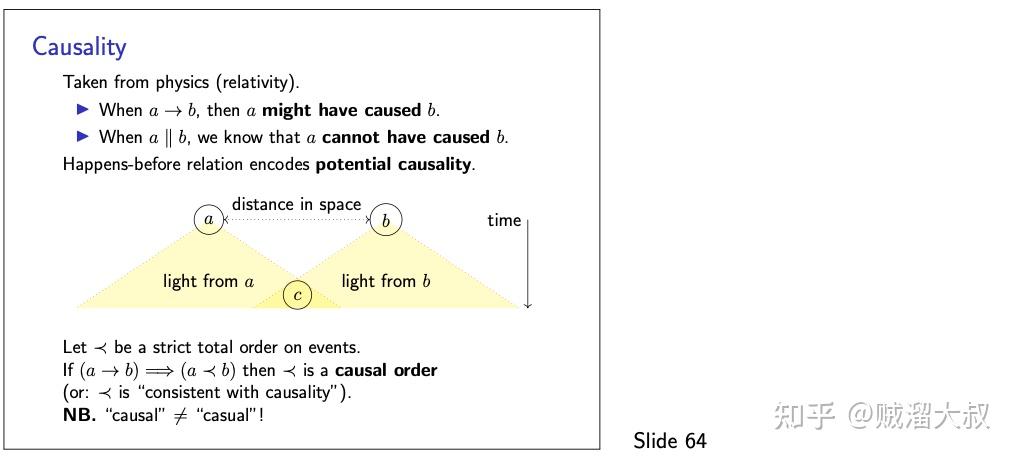
因果关系的概念是从物理学中借鉴来的,在物理学中,人们普遍认为信息传播的速度不可能超过光速。因此,如果你有两个事件 a 和 b,它们在空间上相隔很远,但在时间上却很近,那么从 a 发出的信号不可能在事件 b 之前到达 b 的位置,反之亦然。因此,a 和 b 一定是因果无关的。
一个事件 c 在空间上足够接近 a,在时间上足够长,那么时间 c 将处于 a 的光锥内(light cone):也就是说,a 的信号有可能到达 c,因此 a 可能会影响 c。在分布式系统中,我们通常处理网络上的消息而不是光束,但原理是非常相似的。