什么是字节对齐
计算机中内存大小的基本单位是字节(byte),理论上来讲,可以从任意地址访问某种基本数据类型,但是实际上,计算机并非逐字节大小读写内存,而是以2,4,或8的 倍数的字节块来读写内存,如此一来就会对基本数据类型的合法地址作出一些限制,即它的地址必须是2,4或8的倍数。那么就要求各种数据类型按照一定的规则在空间上排列,这就是对齐。
数据类型对应字节数
下面是不同位数编译器下基本数据类型对应的字节数。
32位编译器:
char:1个字节
char*(即指针变量):4个字节
shortint:2个字节
int:4个字节
unsignedint:4个字节
float:4个字节double:8个字节
long:4个字节
longlong:8个字节
unsignedlong:4个字节
64位编译器:
char:1个字节
char*(即指针变量):8个字节
shortint:2个字节
int:4个字节
unsignedint:4个字节
float:4个字节
double:8个字节
long:8个字节
longlong:8个字节
unsignedlong:8个字节
总结:32 位和 64 位编译器的基本数据类型字节数主要差别在 64 位的指针和 long 为 8 字节。
为什么要字节对齐
无论数据是否对齐,大多数计算机还是能够正确工作,而且从前面可以看到,结构体 test 本来只需要11字节的空间,最后却占用了16字节,很明显 浪费了空间 ,那么为什么还要进行字节对齐呢?
性能提升
以64位系统为例,访问内存的 IO 是以8个字节为单位。现在考虑8字节单位的处理器取 long 类型变量(64位系统),该处理器只能从地址为8的倍数的内存开始读取数据。
假如没有内存对齐机制,数据可以任意存放,现在一个long变量存放在从地址1开始的连续8个字节地址中,该处理器去取数据时,需要完成多个步骤:
- 要先从0地址开始读取第一个8字节块,剔除不想要的字节(0地址)
- 然后从地址8开始读取下一个8字节块,同样剔除不要的数据(9~15地址)
- 最后留下的两块数据合并放入寄存器
现在有了内存对齐的,long类型数据只能存放在按照对齐规则的内存中,比如说0地址开始的内存。那么现在该处理器在取数据时一次性就能将数据读出来了,而且不需要做额外的操作,提高了效率。
空间存储
还是考虑前面的结构体 test,其占用空间大小为16 字节,但是如果我们换一种声明方式,调整变量的顺序,重新运行程序,最后发现结构体 test 占用大小为 12字节
struct test
{
int a;
char b;
short d;
int c;
};
空间存储情况如下,b和d存储在了一个字节块中:
| 0~3 | 4 | 5 | 6~7 | 8~11 |
|---|---|---|---|---|
| a | b | 填充内容 | d | c |
也就是说,如果我们在设计结构的时候,合理调整成员的位置,可以大大节省存储空间。但是需要在空间和可读性之间进行权衡。
跨平台通信
由于不同平台对齐方式可能不同,如此一来,同样的结构在不同的平台其大小可能不同,在无意识的情况下,互相发送的数据可能出现错乱,甚至引发严重的问题。因此,为了不同处理器之间能够正确的处理消息,我们有两种可选的处理方法。
- 1字节对齐
- 自己对结构进行字节填充
我们可以使用伪指令#pragma pack(n)(n为字节对齐数)来使得结构间一字节对齐。
同样是前面的程序,如果在结构体test的前面加上伪指令,即如下:
#pragma pack(1) /*1字节对齐*/
struct test
{
int a;
char b;
int c;
short d;
};
#pragma pack()/*还原默认对齐*/
在这样的声明下,任何平台结构体test的大小都为11字节,这样做能够保证跨平台的结构大小一致,同时还节省了空间,但不幸的是,降低了效率。
当然了对于单个结构体,如下的方法,使其1字节对齐
struct test
{
int a;
char b;
int c;
short d;
}__attribute__ ((packed));
注:
- attribute((aligned (n))),让所作用的结构成员对齐在n字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。
- attribute ((packed)),取消结构在编译过程中的优化对齐,也可以认为是1字节对齐。
除了前面的1字节对齐,还可以进行人为的填充,即test结构体声明如下:
struct test{ int a; char b; char reserve[3]; int c; short d; char reserve1[2];};
访问效率高,但并不节省空间,同时扩展性不是很好,例如,当字节对齐有变化时,需要填充的字节数可能就会发生变化。
内存对齐原则
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。在64位系统中,gcc中默认#pragma pack(8),可以通过预编译命令#pragma pack(n),n = 1,2,4,8,16来改变这一系数。
有效对齐值:是给定值#pragma pack(n)和结构体中最长数据类型长度中较小的那个。有效对齐值也叫对齐单位。c++11中可以通过 alignof(t)来获取。
对齐准则
了解了上面的概念后,我们现在可以来看看内存对齐需要遵循的规则:
(1) 基本类型的对齐值就是其sizeof值;
(2) 结构(struct)(或联合(union))的数据成员,以后每个成员相对于结构体首地址的 offset 都是该成员大小与有效对齐值中较小那个的整数倍;
(3) 结构体的总大小为有效对齐值的整数倍
#include<iostream>
using namespace std;
struct{
char a;
long b;
int c;
short d;
}Test;
int main()
{
cout<<"sizeof(char) "<<sizeof(char)<<endl; // 1
cout<<"sizeof(long) "<<sizeof(long)<<endl; // 8
cout<<"sizeof(int) "<<sizeof(int)<<endl; // 4
cout<<"sizeof(short) "<<sizeof(short)<<endl;// 2
cout<<"alignof(Test) "<<alignof(Test)<<endl;// 8
cout<<"sizeof(Test) "<<sizeof(Test)<<endl;; // 24
return 0;
}
32 位与 64 位区别
1.先看 64 位下:
#include<stdio.h>
struct A
{
int a;
char b;
double c;
char d;
};
struct B
{
char a;
double b;
char c;
};
int main()
{
printf("int =%lu,char=%lu,double=%lu\n",sizeof(int),sizeof(char),sizeof(double));
printf("structA=%lu structB=%lu\n",sizeof(struct A),sizeof(struct B));
return 0;
}
输出结果:
 structA: 4+(1+3)+8+(1+7) = 24
structA: 4+(1+3)+8+(1+7) = 24
structB: (1+7)+8+(1+7) = 24
计算结果与输出是一样的。
这两个结构体在内存中存储应该是下面这样的:
struct A: 整体按照 8 字节(double 长度)对齐
 struct B :
struct B :

2.在 32 位下编译,gcc 加参数 -m32
#include<stdio.h>
struct A
{
int a;
char b;
double c;
char d;
};
struct B
{
char a;
double b;
char c;
};
int main()
{
printf("int =%u,char=%u,double=%u\n",sizeof(int),sizeof(char),sizeof(double));
printf("structA=%u structB=%u\n",sizeof(struct A),sizeof(struct B));
return 0;
}
输出:
 结果和 64 位下完全不一样,很显然它没有按照最长成员 double 的 8 字节对齐。稍微想一下就明白了,因为 32 位只有 4 个字节,最长对齐模数只能按 4 个字节来对齐,double 是分成了 2 个 4 字节。上面两个结构体在内存中应该是这种形式。
结果和 64 位下完全不一样,很显然它没有按照最长成员 double 的 8 字节对齐。稍微想一下就明白了,因为 32 位只有 4 个字节,最长对齐模数只能按 4 个字节来对齐,double 是分成了 2 个 4 字节。上面两个结构体在内存中应该是这种形式。
struct A:整体按照 4 字节对齐
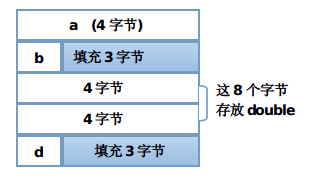 4+(1+3)+8+(1+3) = 20
4+(1+3)+8+(1+3) = 20
struct B :
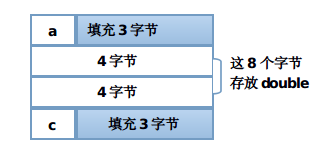 (1+3)+8+(1+3) = 16
(1+3)+8+(1+3) = 16
注意:内存空间实际上是连续的,上面分块的画法只是为了方便理解。
总结
虽然我们不需要具体关心字节对齐的细节,但是如果不关注字节对齐的问题,可能会在编程中遇到难以理解或解决的问题。因此针对字节对齐,总结了以下处理建议:
- 结构体成员合理安排位置,以节省空间
- 跨平台数据结构可考虑1字节对齐,节省空间但影响访问效率
- 跨平台数据结构人为进行字节填充,提高访问效率但不节省空间
- 本地数据采用默认对齐,以提高访问效率
- 32位与64位默认对齐数不一样,分别是4字节和8字节对齐
参考
Fetching Titl59gz
C++内存对齐 | 许森琪的博客
32位和64位下结构体内存对齐问题_lwoyvye的博客-CSDN博客