const currentPage = dv.current().file;
const dailyPages = dv.pages('"0-Daily"').sort(k=>k.file.name, "asc");
const currentPageName = currentPage.name;
const index = dailyPages.findIndex((e) => {return e.file.name === currentPageName});
if (index < 1) {
dv.table(["File", "Created", "Size"],[]);
} else {
const lastIndex = index - 1;
const lastPage = dailyPages[lastIndex].file;
const allPages = dv.pages().values;
const searchPages = [];
const lastTime = dv.parse(lastPage.name);
const currentTime = dv.parse(currentPage.name);
for (let page of allPages) {
const pageFile = page.file;
if (pageFile.cday > lastTime && pageFile.cday <= currentTime) {
searchPages.push(pageFile);
}
}
dv.table(["File", "Created", "Size"], searchPages.sort((a, b) => a.ctime > b.ctime ? 1 : -1).map(b => [b.link, b.ctime, b.size]));
}
后台管理系统 “ContiNew Admin”
ContiNew Admin::GitHub上的宝藏后台管理系统框架,几乎最佳后端规范,前后端分离
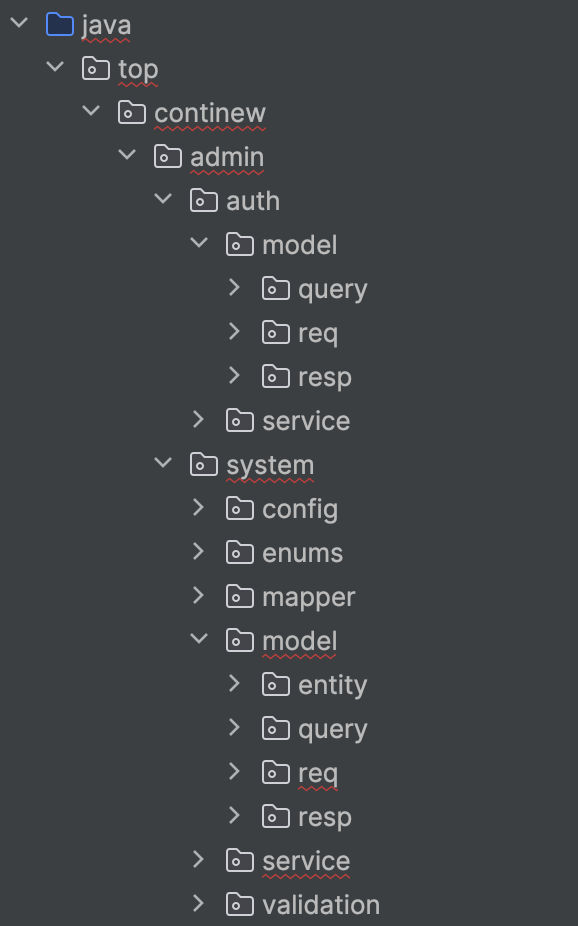
主要看一下是怎么安排的文件目录结构design
entity: 入库的内容
query: 查询的语句
req:请求
resp:响应
小文件合并的必要性和方案
1. 背景
1.1 小文件的定义
在大数据处理和存储中, “小文件” 通常是指文件大小 远小于 HDFS(分布式文件系统)中块(block)大小的文件。一般公司集群的block大小在128MB/256MB这二者的居多,因此,公司对小文件的大小没有一个统一的定义,通常小的不足1MB,大的甚至达到32MB或更大。
1.2 小文件的危害
小文件的危害有很多,这里主要从内存资源、计算资源和系统负载三个方面进行详细阐述:
① 内存资源的浪费 :在HDFS中,每个存储对象block都需要 元数据 来描述其属性(如文件名、大小、权限、时间戳等)和位置信息,大概会占用150字节的空间。大量的小文件会导致元数据的数量急剧增加,这会 占用大量的内存资源 ,并可能导致NameNode(HDFS的元数据管理节点)成为系统的瓶颈, 影响整个集群的性能 。
下图是1个200M的文件在有小文件和没有小文件2种场景下占用的内存空间对比情况:
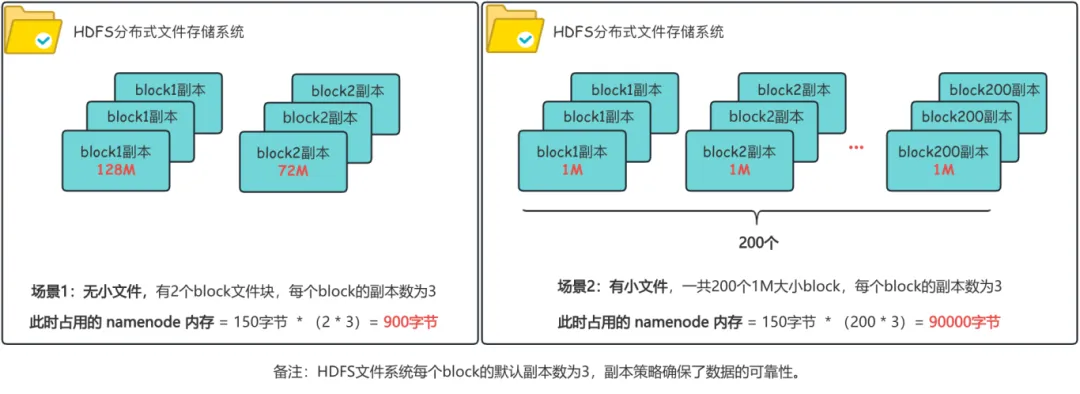
- 无小文件场景下 :有2个block块,每个block块有3个副本,此时占用NameNode的内存为 900字节 ;
- 有大量的小文件场景下: 假设有200个1M的block,每个block块有3个副本,此时占用的NameNode内存为 90000字节 ,相比正常情况下 多出了100倍 的存储空间。
② 计算资源的浪费: 基于 HDFS 文件系统的计算,block 块是最小粒度的数据处理单元,当计算任务读取的数据中存在大量小文件时,会 启动大量Map任务 ,其中Map任务的启动又是非常消耗性能的操作,但是由于文件太小,启动后执行很短时间就停止了,导致 任务启动的时间可能还要大于任务执行的时间 ,极大 浪费 了 计算资源 。
③ 系统负载增加: 短时间读写/创建大量小文件,会造成NameNode节点的瞬时 请求量过大 ,导致处理不及时,进而 增加NameNode的响应时间 ,影响集群性能。
1.3 小文件产生的途径
日常生产中 HDFS 上小文件的产生是一个很正常的事情,有些甚至 不可避免 。下面是产生小文件的常见途径:
- 数据源本身 就包含有大量的小文件,或数据源经过 计算过滤后 变成小文件;
- 流式 数据,如 kafka、sparkstreaming、flink 等流式增量文件,小窗口文件,如几分钟一次等;
- 采用
动态分区也会产生很多小文件,特别是在 过度分区 的场景下。
1.4 如何解决
既然小文件的 危害 如此之 大 ,而且它的 产生 也似乎 不可避免 ,那如何解决小文件问题也显得至关重要。通过1.3节可以知道 小文件 基本都是在 分布式计算场景下产生 的,如果能够在分布式计算的同时避免小文件的产生,那问题也会迎刃而解。公司现在使用的主流分布式计算框架有Hive(底层使用Mapreduce计算)和Spark。
① 在 Hive 中,官方提供了一些官方参数来解决小文件问题,其主要思想是将小文件进行合并,将原始较小的多个小文件合并成一个大文件。Hive中解决小文件问题的 三板斧 分别是:(第三章详细阐述)
- 对 输入小文件进行合并 - 通过配置 CombineHiveInputFormat 等参数实现
- 对 输出小文件进行合并 - 通过配置 merge 参数实现
- 对 输出小文件进行合并 - 通过在代码中加入 distribute by
② 而在 Spark 中,并没有像Hive那样官方参数来直接解决小文件问题,但解决小文件的底层原理是相通的,下面是Spark中二种主流的解决方案 : (第五章详细阐述)
- 使用 S park扩展功能 实现
- 自定义一个包含小文件合并功能的 commitProtocolClass 协议类
Apache Commons Primitives
Commons Primitives是Apache基金会开发的一个轻量级Java库,专门用来处理基本数据类型(如int、long、double等)的集合和工具类。它的设计理念是”让基本类型更好用”。简单来说,它能让我们在使用基本数据类型时少写很多重复代码。