const currentPage = dv.current().file;
const dailyPages = dv.pages('"0-Daily"').sort(k=>k.file.name, "asc");
const currentPageName = currentPage.name;
const index = dailyPages.findIndex((e) => {return e.file.name === currentPageName});
if (index < 1) {
dv.table(["File", "Created", "Size"],[]);
} else {
const lastIndex = index - 1;
const lastPage = dailyPages[lastIndex].file;
const allPages = dv.pages().values;
const searchPages = [];
const lastTime = dv.parse(lastPage.name);
const currentTime = dv.parse(currentPage.name);
for (let page of allPages) {
const pageFile = page.file;
if (pageFile.cday > lastTime && pageFile.cday <= currentTime) {
searchPages.push(pageFile);
}
}
dv.table(["File", "Created", "Size"], searchPages.sort((a, b) => a.ctime > b.ctime ? 1 : -1).map(b => [b.link, b.ctime, b.size]));
}
DDL 和 DML 的区别
DML(Data Manipulation Language)数据操纵语言:
适用范围:对数据库中的数据进行一些简单操作,如 insert,delete,update,select 等.
DDL(Data Definition Language)数据定义语言:
适用范围:对数据库中的某些对象(例如,database,table)进行管理,如 Create,Alter 和 Drop.
一、DDL(数据定义语言,Data Definition Language)
建库、建表、设置约束等:create\drop\alter
1、创建数据库:
create database IF NOT EXISTS hncu CHARACTER SET utf8;
2、创建表格:
use hncu;
create table IF NOT EXISTS stud(
id int,
name varchar(30),
age int
);
3、更改表结构(设置约束)
desc stud; //查看表结构
alter table stud drop column age;
alter table stud add column age int;
4、删除表、删除数据库
drop table stud;
drop database hncu;
二、DML (数据操纵语言,Data Manipulation Language )
主要指数据的增删查改: Select\delete\update\insert\call
select * from stud;
select name,age from stud; //查询指定的列
select name as 姓名, age as 年龄 from stud;
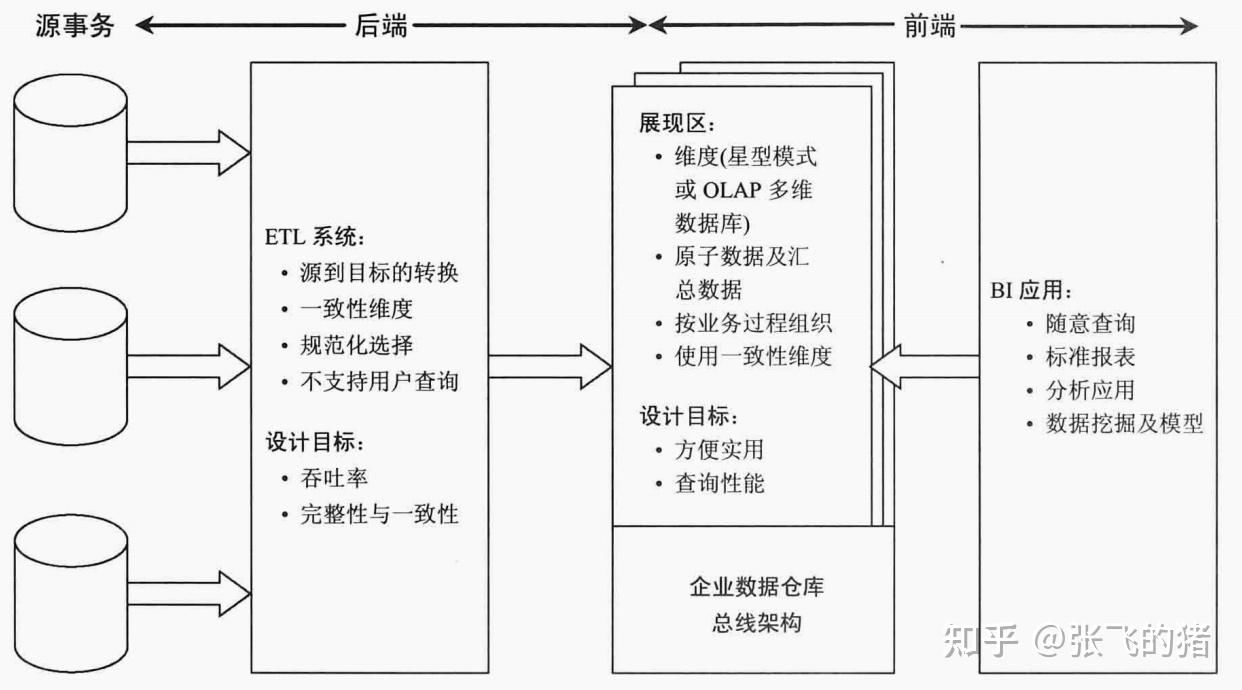
数仓是什么
数据仓库,简称数仓,英文名称为 Data Warehouse,可简写为 DW 或 DWH。
数据仓库就是可以理解就是一个使用仓库,数据就是这个仓库的货物,而数据仓库的开发人员就是这个仓库的管理员,所以数据仓库就是一个怎么管理好数据,使得数据规范的放在仓库中,便于 BI、AI 等其他的使用数据的方面可以更好的使用仓库里面的数据,使得数据发挥出更好的价值,显而易见在一堆有规律,整齐的货物里面找一个东西,要比在没有整理的里面找更加有效率。
一. 各种名词解释
1.1 ODS是什么?
- ODS层最好理解,基本上就是数据从源表拉过来,进行etl,比如mysql 映射到hive,那么到了hive里面就是ods层。
- ODS 全称是 Operational Data Store,操作数据存储.“面向主题的”,数据运营层,也叫ODS层,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的 ETL 之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。但是,这一层面的数据却不等同于原始数据。在源数据装入这一层时,要进行诸如去噪(例如有一条数据中人的年龄是 300 岁,这种属于异常数据,就需要提前做一些处理)、去重(例如在个人资料表中,同一 ID 却有两条重复数据,在接入的时候需要做一步去重)、字段命名规范等一系列操作。
1.2 数据仓库层DW?
数据仓库层(DW),是数据仓库的主体.在这里,从 ODS 层中获得的数据按照主题建立各种数据模型。这一层和维度建模会有比较深的联系。
细分:
- 数据明细层:DWD(Data Warehouse Detail)
- 数据中间层:DWM(Data WareHouse Middle)
- 数据服务层:DWS(Data WareHouse Servce)
1.2.1 DWD明细层?
明细层(ODS, Operational Data Store,DWD: data warehouse detail)
- 概念:是数据仓库的细节数据层,是对STAGE层数据进行沉淀,减少了抽取的复杂性,同时ODS/DWD的信息模型组织主要遵循企业业务事务处理的形式,将各个专业数据进行集中,明细层跟stage层的粒度一致,属于分析的公共资源
- 数据生成方式:部分数据直接来自kafka,部分数据为接口层数据与历史数据合成。
- 这个stage层不是很清晰
1.2.2 DWM 轻度汇总层(MID或DWB, data warehouse basis)
- 概念:轻度汇总层数据仓库中DWD层和DM层之间的一个过渡层次,是对DWD层的生产数据进行轻度综合和汇总统计(可以把复杂的清洗,处理包含,如根据PV日志生成的会话数据)。轻度综合层与DWD的主要区别在于二者的应用领域不同,DWD的数据来源于生产型系统,并未满意一些不可预见的需求而进行沉淀;轻度综合层则面向分析型应用进行细粒度的统计和沉淀
- 数据生成方式:由明细层按照一定的业务需求生成轻度汇总表。明细层需要复杂清洗的数据和需要MR处理的数据也经过处理后接入到轻度汇总层。
- 日志存储方式:内表,parquet文件格式。
- 日志删除方式:长久存储。
- 表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
- 库与表命名。库名:dwb,表名:初步考虑格式为:dwb日期业务表名,待定。
- 旧数据更新方式:直接覆盖
1.2.3 DWS 主题层(DM,data market或DWS, data warehouse service)
- 概念:又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
- 数据生成方式:由轻度汇总层和明细层数据计算生成。
- 日志存储方式:使用impala内表,parquet文件格式。
- 日志删除方式:长久存储。
- 表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
- 库与表命名。库名:dm,表名:初步考虑格式为:dm日期业务表名,待定。
- 旧数据更新方式:直接覆盖
1.3 APP 层 & ADS 层
数据产品层(APP),这一层是提供为数据产品使用的结果数据。
也叫 ADS 层,数据应用层(ADS,Application Data Store):数据仓库中最终提供给企业用户的数据接口
主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、Mysql 等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。
如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。
应用层(App)
- 概念:应用层是根据业务需要,由前面三层数据统计而出的结果,可以直接提供查询展现,或导入至Mysql中使用。
- 数据生成方式:由明细层、轻度汇总层,数据集市层生成,一般要求数据主要来源于集市层。
- 日志存储方式:使用impala内表,parquet文件格式。
- 日志删除方式:长久存储。
- 表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
- 库与表命名。库名:暂定apl,另外根据业务不同,不限定一定要一个库。(其实就叫app_)就好了
- 旧数据更新方式:直接覆盖。
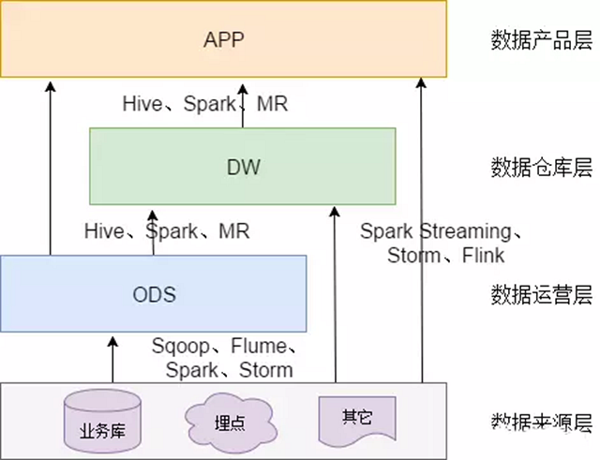
1.4 数据的来源
数据主要会有两个大的来源:
业务库,这里经常会使用 Sqoop 来抽取
我们业务库用的是databus来进行接收,处理kafka就好了。
在实时方面,可以考虑用 Canal 监听 Mysql 的 Binlog,实时接入即可。(有机会补一下这个canal)
埋点日志,线上系统会打入各种日志,这些日志一般以文件的形式保存,我们可以选择用 Flume 定时抽取,也可以用用 Spark Streaming 或者 Storm 来实时接入,当然,Kafka 也会是一个关键的角色。
还有使用filebeat收集日志,打到kafka,然后处理日志
注意: 在这层,理应不是简单的数据接入,而是要考虑一定的数据清洗,比如异常字段的处理、字段命名规范化、时间字段的统一等,一般这些很容易会被忽略,但是却至关重要。特别是后期我们做各种特征自动生成的时候,会十分有用。
1.5 ODS、DW → App层
这里面也主要分两种类型:
- 每日定时任务型:比如我们典型的日计算任务,每天凌晨算前一天的数据,早上起来看报表。 这种任务经常使用 Hive、Spark 或者生撸 MR 程序来计算,最终结果写入 Hive、Hbase、Mysql、Es 或者 Redis 中。
- 实时数据:这部分主要是各种实时的系统使用,比如我们的实时推荐、实时用户画像,一般我们会用 Spark Streaming、Storm 或者 Flink 来计算,最后会落入 Es、Hbase 或者 Redis 中。
1.6 维表层DIM?
维表层(Dimension)
最后补充一个维表层,维表层主要包含两部分数据:高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。
1.7 层级的简单分层图
见下图,对DWD层在进行加工的话,就是DWM层(MID层)(我们的数仓还是有很多dwm层的)
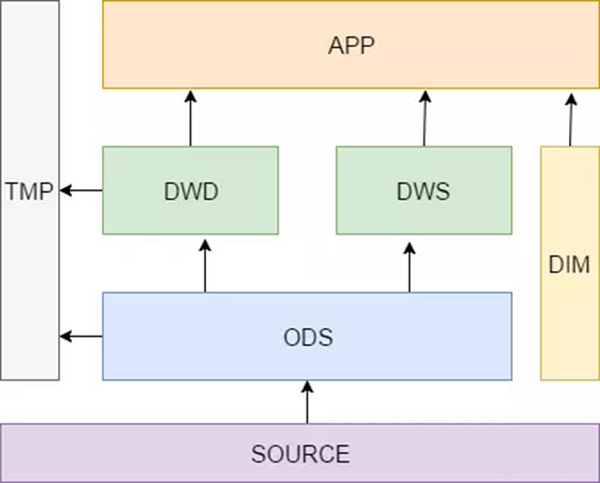
这里解释一下DWS、DWD、DIM和TMP的作用。
- DWS:轻度汇总层,从ODS层中对用户的行为做一个初步的汇总,抽象出来一些通用的维度:时间、ip、id,并根据这些维度做一些统计值,比如用户每个时间段在不同登录ip购买的商品数等。这里做一层轻度的汇总会让计算更加的高效,在此基础上如果计算仅7天、30天、90天的行为的话会快很多。我们希望80%的业务都能通过我们的DWS层计算,而不是ODS。
- DWD:这一层主要解决一些数据质量问题和数据的完整度问题。比如用户的资料信息来自于很多不同表,而且经常出现延迟丢数据等问题,为了方便各个使用方更好的使用数据,我们可以在这一层做一个屏蔽。(汇总多个表)
- DIM:这一层比较单纯,举个例子就明白,比如国家代码和国家名、地理位置、中文名、国旗图片等信息就存在DIM层中。
- TMP:每一层的计算都会有很多临时表,专设一个 DWTMP 层来存储我们数据仓库的临时表。
