消息队列在设计之初就给业务规划好了一条康庄大道:
- 主业务链路作为 Producer 发出消息
- 数十个甚至更多 Consumer 订阅该消息,分别执行自己快速且幂等的原子逻辑
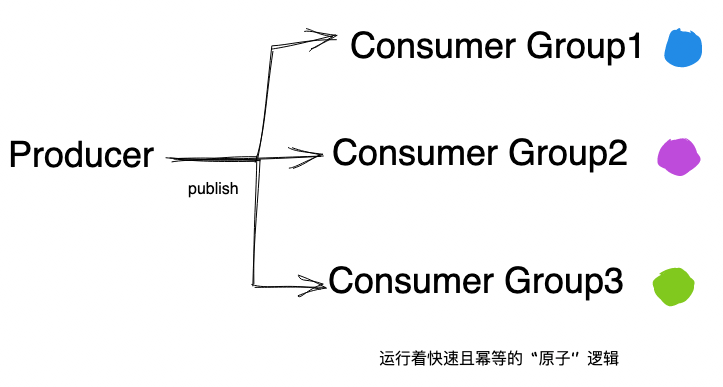
在这种设计下,每个订阅者的逻辑相互隔离,互不影响;能够独立地重试,保证自己的一致性。
现实并不总像上面幻想的那样,随着业务发展常会出现一些 “大泥球” 消费者。
以钉钉审批为例,为了优化产品体验,在审批单发起后,还要消费审批单发起消息,异步做一系列的事情,比如发消息通知,同步搜索引擎,更新提示红点等等,这些功能随着产品迭代只会越叠越多,最后成为一个同时做十几件事情的 “大泥球” 消费者。
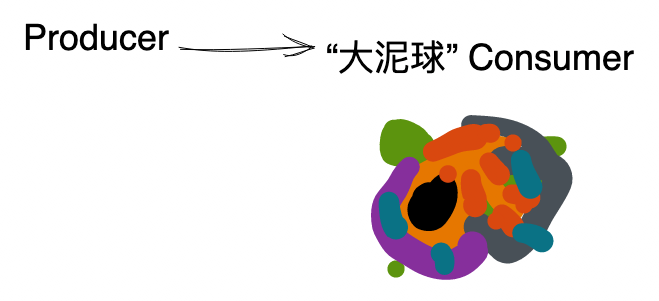
大泥球 Consumer 对系统和用户都有巨大的损害:
- 逻辑相互影响,修改风险高;
- 链路脆弱,容易中断,一个调用失败,后续所有逻辑将不会执行;
- 没有重试:大泥球无法做到原子和幂等,整体重试代价太大,所以直接异步执行放弃重试
- 消息队列引以为傲的重试功能反而会成为故障的温床,导致雪崩。
- 为什么不直接把大泥球拆分成前面的多个 Consumer 呢?这确实也是一种方案,但是对于大泥球 Consumer,可能会拆出几十个 Consumer,这会导致非常严重的读扩散。举个例子,审批单发起的消息中只含有审批单的 id,内容需要从数据库反查,原本在“大泥球”中,只需要查询一次就复用,而拆分后可能要多查几十次。这还只是众多扩散问题的其中一个,如果为了治理大泥球,却加重了扩散问题,就得不偿失了。
正文
1、将堆砌在一起的逻辑 拆分 成一个个业务 Listener 类(详见 “朴素的拆分想法” 章节);
2、当有业务 Listener 失败时,可以实现失败业务 精准重试 ,而不是粗暴地全部重试(详见 “精准重试” 章节);
3、 高性能 地构建 Listener 的统一上下文,降低读扩散,并且避免其随着迭代腐化(详解 “统一上下文” 章节);
4、最后,本文的实践不需要额外的存储,也不需要建立额外的 Consumer,原来的基础设施可以直接复用;
朴素的拆分想法
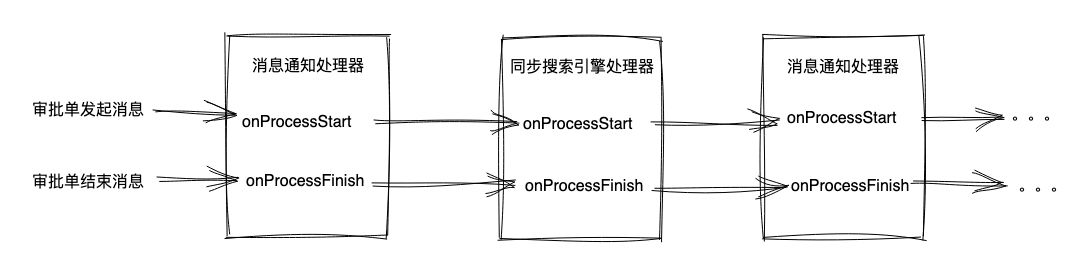
- 某个处理器因为网络超时失败了,如何重试?:我们仅仅是将逻辑拆开了,执行的时候还是一串 “大泥球”,如果仅仅依靠消息队列本身机制,要重试只能一起重试,这显然无法满足诉求;
- 如何高性能地构建庞大的统一上下文(即 Context 参数):为了满足众多处理器对数据查询的诉求,需要提供庞大的上下文,除了性能风险外,也是代码腐败的温床
我们常常出于技术性能而不是业务去设计上下文中的字段,这是上下文腐化的根本原因。
统一上下文
- 为了满足所有处理器的需求,上下文往往会很庞大,因此 构建性能差。
- 外部 无法感知处理器内部需要使用上下文的哪些字段 ,只能一股脑地将所有字段都填充好,传递进去,而且内部很有可能一个字段都不使用,白白损耗了性能。
- 上下文中存在一些 幽灵字段 ,在某个处理器中设置进去,又在某几个处理器中读取,也就是它有时候为 null,有时候又有值,维护难度巨大,从中取个值都要战战兢兢。
- 读扩散 问题:每个处理器都去读相同的数据,导致链路数十倍的读扩散。
懒加载
前两个问题可以通过引入懒加载机制解决,对于上下文中性能损耗比较大的字段,在读取时再进行加载。这样上下文的构建就非常快了 ,也不会去额外加载处理器中用不到的字段。
详见 函数式编程+惰性代码
基于业务设计字段
什么叫 “基于技术” 设计字段? 举个例子,之前审批也有类似的 上下文 + 处理器 的架构。但是因为不知道处理器中会用哪些字段,为了优化上下文的性能,在上下文中只放置了一个审批单 id,所有数据都需要在处理器中额外查询,造成了严重的读扩散。为了优化性能还容易引入幽灵字段,幽灵字段在上下文中的初始值为 null,处理器在需要时才将其设置进去。
通过字段懒加载机制,业务不再需要妥协于技术,可以将字段放在它业务上 “应该在” 的地方。 字段放在实体中的原因,不是为了方便取用,也不是为优化性能,而是业务上它就应该在那里。 这也是 DDD 的核心思想。
审批业务的特点就是层次鲜明,一个审批单由多个活动组成,而一个活动由多个任务组成。
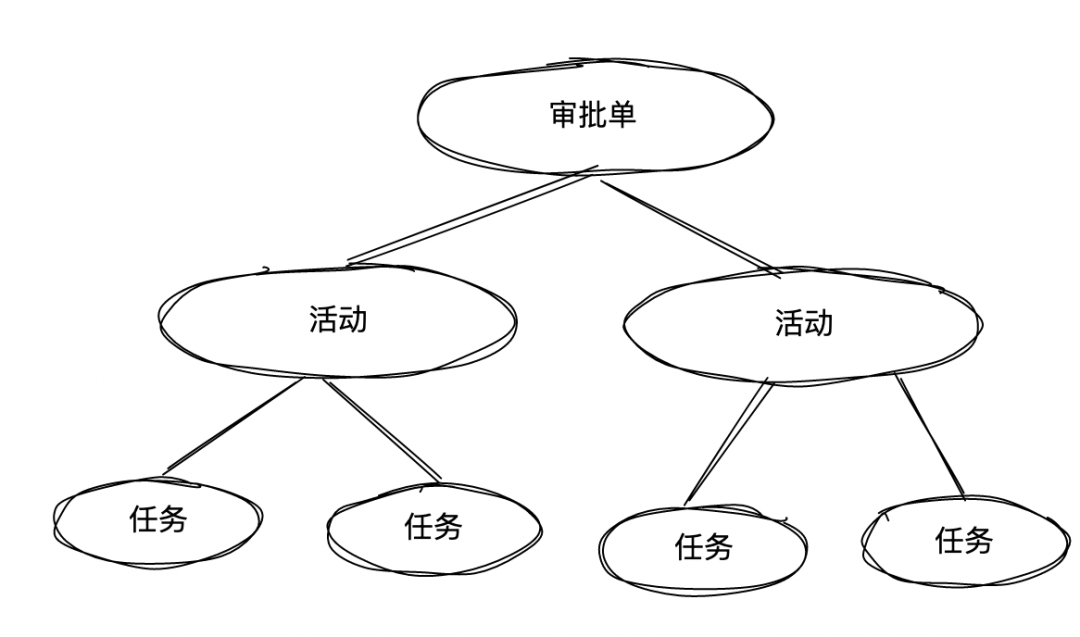
根据这个特点,我们针对不同的审批事件消息设计了三种上下文:
- 审批单实例上下文
- 审批单发起消息
- 审批单结束消息
- 审批单撤销消息
- …
- 活动上下文
- 活动开始消息
- 活动结束消息
- …
- 任务上下文
- 任务开始消息
- 任务结束消息
- 任务取消消息
- …
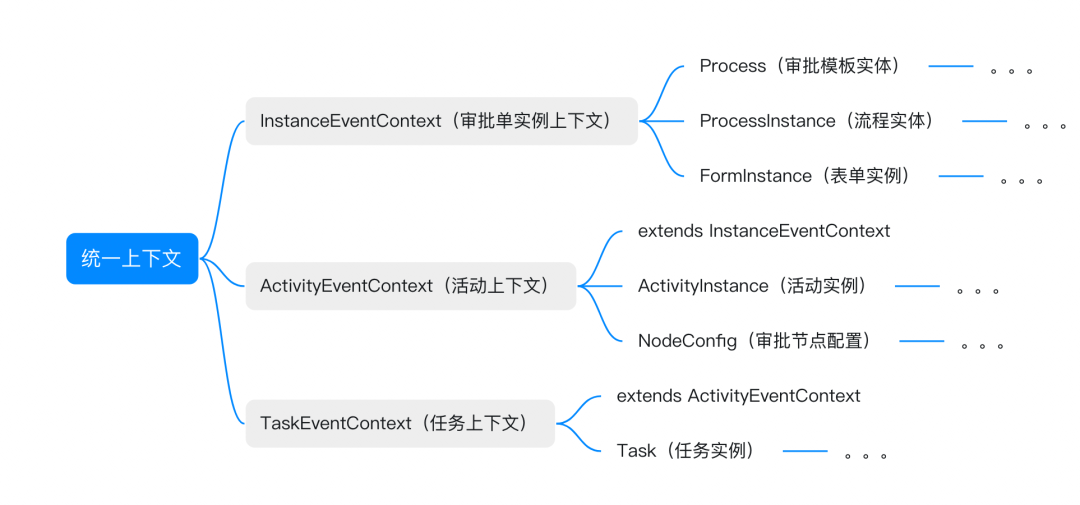
上下文全部设计成不可变的,不允许一个处理器设置字段,另一个处理器又去读取字段的情况,如果实在需要,说明这两个处理器是耦合的,那么合并成一个处理器更加合适。
至此,我们将字段都放在业务上应该在地方,开发者只要根据自己对业务的理解就可以一层层地找到字段,并且肯定能获取到,不会有的时候存在,有的时候又不存在。
总结
本篇文章的另一个感受是,写业务和写框架的不同之处。
写框架是要面面俱到,写业务就要贴近业务。
Producer -> Consumber 的消息队列设计有问题么?从框架层面上看应该是没有问题的,灵活性极强。
但是当各种灵活性叠加起来后,整个的可读性就开始变差。
这个时候,如果想要对业务的可维护性做优化,就需要开始封装逻辑,从业务角度出发的逻辑会更加的易读。