问题场景
日常工作跟分布式存储相关,遇到这样一个业务场景:
将大文件通过 HTTP 协议传输到服务端。无法一次加载到内存中,组装到 Request 的 body 中。
针对这样的问题,应该怎么解决呢?最简单的思路就是分而治之,将大文件分割成小文件上传,但是同一个大文件显然不能通过多次 HTTP 请求发送(这样会被认为是多个文件)。
HTTP 流式传输为我们提供了相应的解决方案。
先来看几个知识点:
KeepAlive模式
大学的知识学完,对 HTTP 的认知只停留在了少数几个关键词:HTTP 是无状态无连接的。
无连接的意思是指HTTP协议采用“请求-应答”模式,当使用普通模式,即非KeepAlive模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接;
后来 Web 的世界越来越精彩,一个网页中可能嵌套了多种资源,比如图片、视频,为了解决频繁建立 TCP 连接带来的性能损耗,出现了 Keep-Alive 模式。当使用Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
HTTP 本身是无状态的,那么Keep-Alive 的功能必然是依赖 TCP 来实现的。TCP 的实现中包含一个 Keep-Alive 定时器,当一条数据流中没有数据通过时,服务端每隔一段时间会向客户端发送一个不带数据的 ACK 请求,如果收到 Client回复,表明连接依然存在。如果没有收到回复,Server会多次 ACK,达到一定次数以后还没有收到回复,默认此连接关闭。
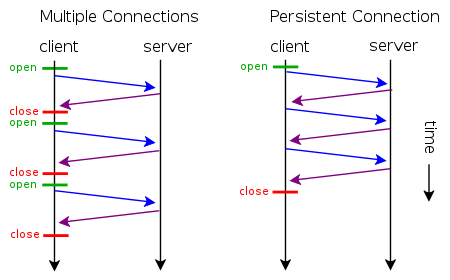
另外需要说明的是,Keep-Alive 模式在HTTP 1.0中默认是关闭的,需要在HTTP头加入”Connection: Keep-Alive”,才能启用Keep-Alive;HTTP 1.1中默认启用Keep-Alive,如果加入”Connection: close “,才关闭。但是若想完成一次 Keep-Alive 的连接,仍旧需要 Client 和 Server 端共同支持,如果某一端处理完请求直接关闭了 Socket,神仙也保证不了连接。
大文件的上传既然不可能一次性放到 RequestBody 中传输,那么就避免不了多次传输。Keep-Alive 模式解决了不必重复频繁建立连接的问题,第二个问题随之而来,怎么判断数据流的结束?
在请求-响应模式下,每一次 HTTP 请求发送完成,Client 都会主动关闭连接,Server 端在读取完所有的 Body 数据后,就认为此次请求已经完毕,开始在服务端进行处理。但是在 Keep-Alive模式下,这个问题显然就没有这么简单了。举个例子,比如一条 Keep-Alive 的HTTP 连接 ,通过底层的 TCP 通道连续发送了两张图片,对于服务器来说,如何判断这是两张图片?而不是把他们当做同一个文件的数据进行处理呢?再比如,普通模式下,客户端请求服务器的数据,服务端发送完响应就会关闭连接,客户端读取时会读到 EOF(-1),这个时候客户端就会关闭自身的连接。但在 Keep-Alive 模式下,服务器不会主动关闭连接,Client 自然也就读不到 EOF,客户端该如何判断数据流的结束呢。
判断数据流结束的方法
HTTP 为我们提供了两种方式
-
Content-Length
这是一个很直观的方式,在要传输的数据前增加一个信息,来告知对端将要传输多少数据,这样在另一侧读取到这个长度的数据后,可以认为接受已经完成。
如果无法提前预知Content-Length 呢,比如数据源还在不断的生成当中,不知道什么时候会结束。接下来还有第二种办法。
-
使用消息Header 字段,Transfer-Encoding:chunk
如果要一边产生数据,一边发给客户端,服务器就需要使用”Transfer-Encoding: chunked”这样的方式来代替Content-Length。
chunk编码将数据分成一块一块的发出。Chunked编码将使用若干个Chunk串连而成,由一个标明 长度为0 的chunk标示结束。每个Chunk分为头部和正文两部分,头部内容指定正文的字符总数( 十六进制的数字 )和数量单位(一般不写),正文部分就是指定长度的实际内容,两部分之间用 回车换行(CRLF) 隔开。在最后一个长度为0的Chunk中的内容是称为footer的内容,是一些附加的Header信息(通常可以直接忽略)。
抓包验证
百闻不如一见,使用 WireShark 先抓为敬。
chunk 编码方式抓包:
Server 编码:
func indexHandler(w http.ResponseWriter, r *http.Request) {
//fmt.Print(r.Body.Read())
fmt.Fprint(w, "hello world")
}
func main() {
http.HandleFunc("/report", indexHandler)
http.ListenAndServe(":8000", nil)
}
Client 代码
func main() {
pr, rw := io.Pipe()
go func(){
for i := 0; i < 100; i++ {
rw.Write([]byte(fmt.Sprintf("line:%drn", i)))
}
rw.Close()
}()
http.Post("localhost:8000/","text/pain", pr)
}
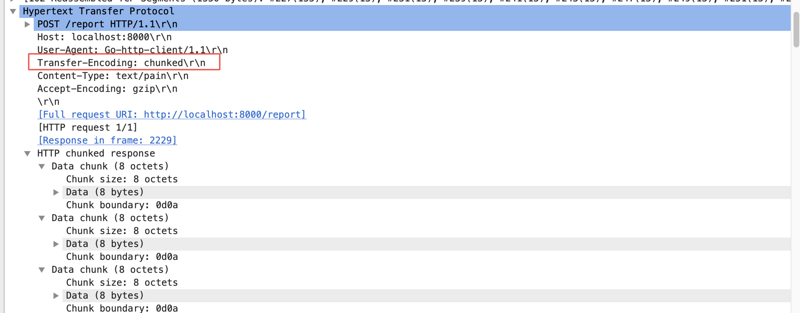

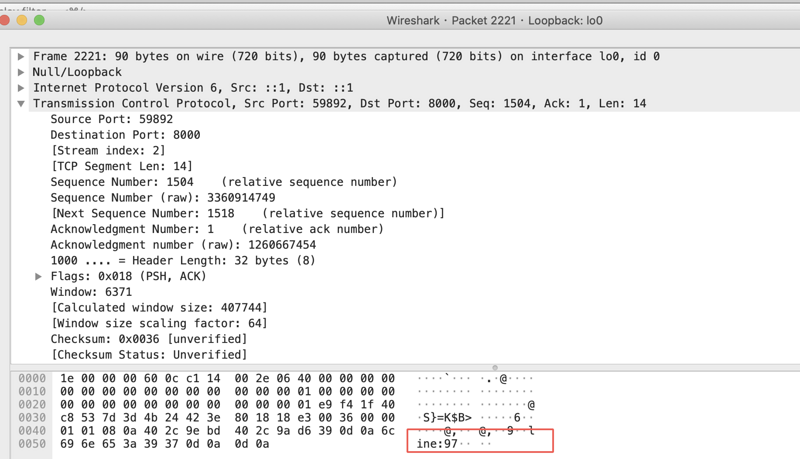
从结果可以看出,HTTP 协议底层通过同一个 TCP 连接在发送数据。
每一个TCP packet 的内容为我们写入的数据。
方式二:Content-Length
Client编码
func main() {
count := 10
line := []byte("linern")
pr, rw := io.Pipe()
go func() {
for i := 0; i < count; i++ {
rw.Write(line)
time.Sleep(500 * time.Millisecond)
}
rw.Close()
}()
// 构造request对象
request, err := http.NewRequest("POST", "http://localhost:8000/report", pr)
if err != nil {
log.Fatal(err)
}
// 提前计算出ContentLength
request.ContentLength = int64(len(line) * count)
// 发起请求
http.DefaultClient.Do(request)
}


当然底层依然是通过多次 tcp 包传输的。
总结
为了解决不能将大数据一次性拼接到 Request 的 Body 中这个问题,采取了 HTTP 流式传输的方式,即边读进内存,边通过 HTTP 传输。
Keep-Alive 模式,避免了传输多个报文时,TCP 连接重复建立,为流式传输大量数据打好了基础。
Content-Length 和 Transfer-Encoding,两种方式为消息内容的长度判断提供了解决方案。
设置Content-Length的方式,由 Client 端持续将数据通过 HTTP 传输到 Server。chunk方式,Client 端将数据分片发包到 Server。
以上的方式都是通过建立一次 HTTP 传输完成的。