如下结构的一张表,表中约有104w行数据:
CREATE TABLE `test03` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`dept` tinyint(4) NOT NULL COMMENT '部门id',
`name` varchar(30) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '用户名称',
`create_time` datetime NOT NULL COMMENT '注册时间',
`last_login_time` datetime DEFAULT NULL COMMENT '最后登录时间',
PRIMARY KEY (`id`),
KEY `ct_index` (`create_time`))
ENGINE=InnoDB
AUTO_INCREMENT=1048577
DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
COMMENT='测试表'
查询1,并未用到 ct_index(create_time) 索引:
- type 为 ALL ,而不是 range
- rows 行数和全表行数接近
# 查询1
mysql> explain select * from test03 where create_time > '2021-10-01 02:04:36';
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | test03 | NULL | ALL | ct_index | NULL | NULL | NULL | 1045955 | 50.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
而查询2,则用到了 ct_index(create_time) 索引:
# 查询2
mysql> explain select * from test03 where create_time < '2021-01-01 02:04:36';
+----+-------------+--------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | test03 | NULL | range | ct_index | ct_index | 5 | NULL | 169 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
这里可以看到 rows 的数量是完全不一样的,这就是为什么 查询 2 使用 index , 查询 1 没有使用的原因。
这里使用 optimizer trace 工具,观察 MySQL 对 SQL 的优化处理过程:
通过逐行阅读,发现优化器在 join_optimization(SQL 优化阶段)部分的 rows_estimation 内容里:
- 明确指出了使用索引 ct_index(create_time) 和全表扫描的成本差异
- 同时指出了未选择索引的原因:cost
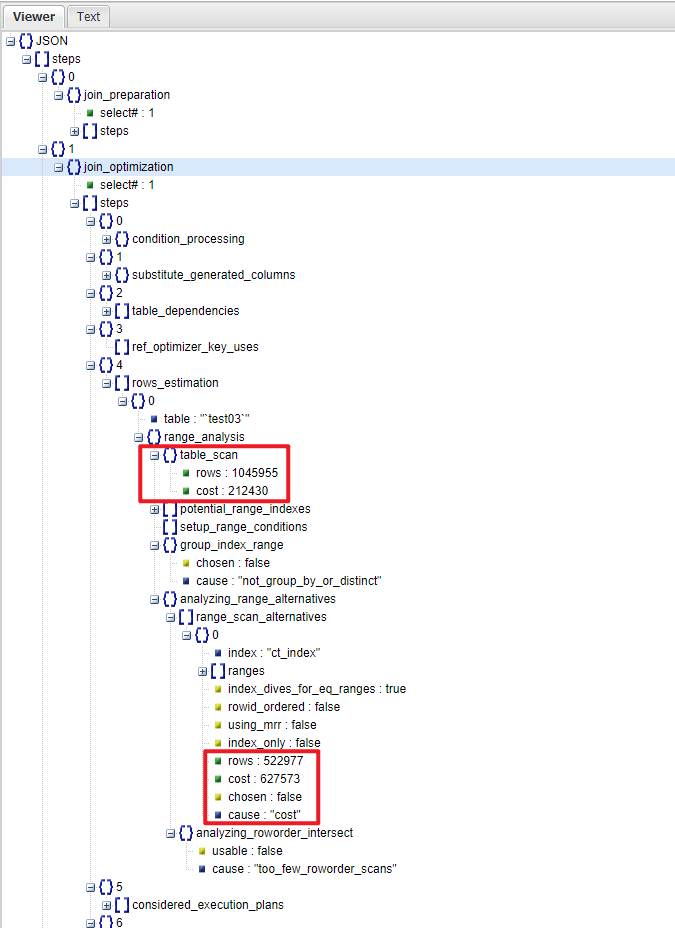
通过观察优化器的信息,不难发现,使用索引扫描行数约 52w 行,而全表扫描约为 104w 行。
为什么优化器反而认为使用索引的成本比全表扫描还高呢?
因为当 ct_index(create_time) 这个普通索引并不包括查询的所有列,因此需要通过 ct_index 的索引树找到对应的主键 id ,然后再到 id 的索引树进行数据查询,即回表(通过索引查出主键,再去查数据行),这样成本必然上升。
这里可以回头看查询 1 和查询 2 的数据量占比:
- 查询 1 的数据量占整个表的 60%,回表成本高,因此优化器选择了全表扫描
- 查询 2 的数据量占整个表的 0.02%,因此优化器选择了索引
另外,在 MySQL 的官方文档中对此也有简要的描述:
- 当优化器认为全表扫描成本更低的时候,就不会使用索引
- 并没有一个固定的数据量占比来决定优化器是否使用全表扫描(曾经是30%)
- 优化器在选择的时候会考虑更多的因素,如:表大小,行数量,IO块大小等