背景
不久前的一次压测,一个接口的 TPS 在 100 并发下不足 500,且延时超过 500MS,这个接口的性能远远低于我们的预期。
对应的接口是一个极为简单的接口,只做了两件事情:
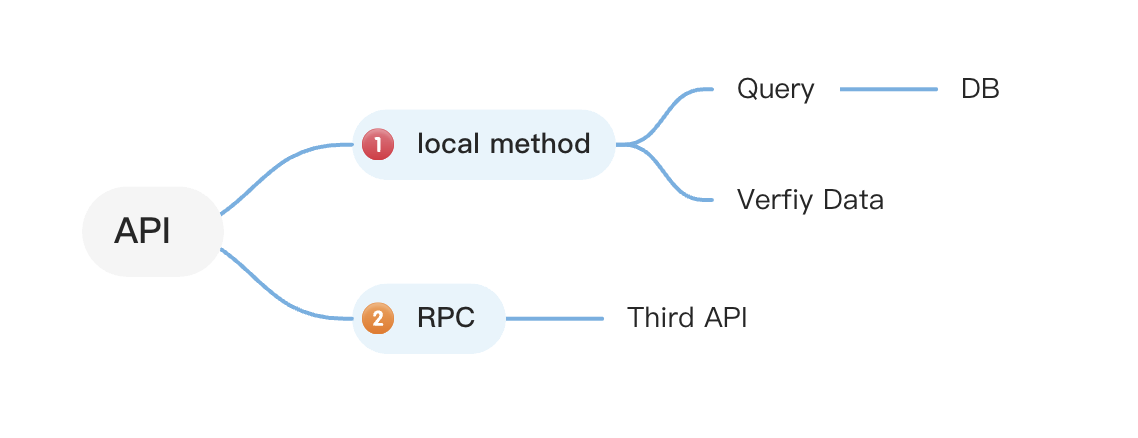
- 从数据库中读取一条数据,做了一些简单的处理
- 进行一次 HTTP 调用
那么话不多说,开始从内到外几个排查:
- DB 的 CPU、内存、磁盘 IO、网络 IO 等指标一切正常:排除慢 sql 相关问题
- POD,即容器的 CPU、内存、网络 IO 等指标一切正常:排除容器资源不足问题
- JVM 的 Heap Size 即堆内存、GC、线程数等指标一切正常:排除内存泄漏、GC 问题
- 利用 Arshas 或其他监测工具生成火焰图或接口耗时分析图,发现接口耗时主要集中第二步
Stream Reset Exception
上文提到发现接口的主要耗时集中在第二步,那么我们就从第二步开始分析:
- 排查发现,该 Http 调用使用的是 Okhttp3, 且使用的是默认的连接池,最多复用 5 个连接,看起来有点太少了,
但后续调整到 100 后发现性能并没有提升,所以这个问题基本可以排除。(当然连接池确实过小,但是与此次的性能问题并无关系)
@Configuration
public class RestTemplateConfig {
@Bean
public RestTemplate restTemplate() {
return new RestTemplate(new OkHttp3ClientHttpRequestFactory());
}
}- 开启 Okhttp 的日志,发现有大量的 Stream Reset Exception,出现该异常的概率大概在10%
Caused by: okhttp3.internal.framed.StreamResetException: stream was reset: CANCEL
at okhttp3.internal.framed.FramedStream.getResponseHeaders(FramedStream.java:145)
at okhttp3.internal.http.Http2xStream.readResponseHeaders(Http2xStream.java:149)
at okhttp3.internal.http.HttpEngine.readNetworkResponse(HttpEngine.java:775)
at okhttp3.internal.http.HttpEngine.access$200(HttpEngine.java:86)
at okhttp3.internal.http.HttpEngine$NetworkInterceptorChain.proceed(HttpEngine.java:760)
at okhttp3.internal.http.HttpEngine.readResponse(HttpEngine.java:613)
at okhttp3.RealCall.getResponse(RealCall.java:244)
at okhttp3.RealCall$ApplicationInterceptorChain.proceed(RealCall.java:201)
at okhttp3.RealCall.getResponseWithInterceptorChain(RealCall.java:163)
at okhttp3.RealCall.execute(RealCall.java:57)至此,上游 API 的同学已经传来了消息,他们的接口一切正常,响应时间 99%在 20ms 以内,那么问题基本可以收敛至从发起调用到接收到响应的这段时间,即从 Okhttp 到上游 API 的这段时间。
Http2
通过上文的 Stream Reset Exception 可以发现,该 Http 调用使用的是 h2协议,与平时的内部 RPC 并不一样。这也是该问题第一次出现的原因。
什么是 Http2 协议
HTTP/2 是 HTTP 协议自 1999 年 HTTP 1.1 发布后的首个更新,主要基于 SPDY 协议。1 它具有以下几个特点:
- 二进制分帧:HTTP/2 采用二进制格式传输数据,而非 HTTP 1.x 的文本格式。
- 多路复用:HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。
- 头部压缩:HTTP/2 对消息头采用 HPACK 进行压缩传输,能够节省消息头占用的网络流量。
- 服务器推送:服务端可以在发送页面 HTML 时主动推送其他资源,而不用等到浏览器解析到相应位置,发起请求再响应。
这些特点使得 HTTP/2 在性能上有了很大的提升。
在这里解释一下为何上文提到,即使连接池大小只有5,但是对于这次的场景并不是瓶颈,因为在理想情况下,无论并发是多少,http2由于支持多路复用,所以并发调用仅需一条tcp连接,根本不需要连接池!!!
为什么会出现 Stream Reset Exception
至此,调用方的问题已经排查完毕,那么问题就转移到了上游 API,我们来看下上游 API 背后的拓扑结构:
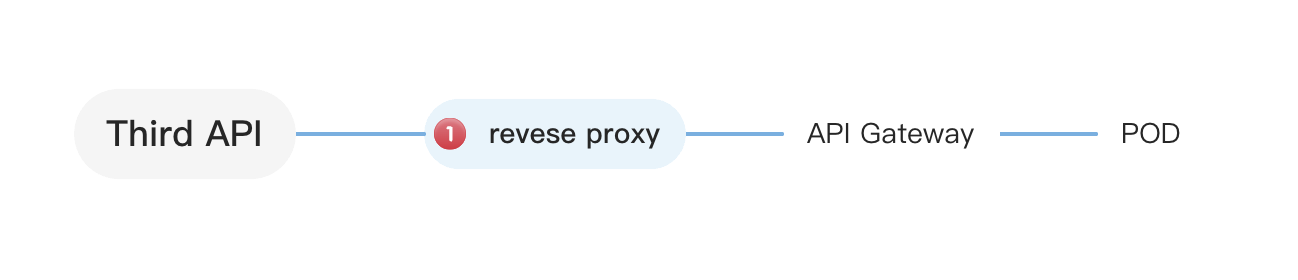
通过对上游 API 的压测,发现从 API Gateway→POD 这一侧压测接口正常,但是从 Reverse Proxy→API Gateway→POD 这一侧压测接口就会出现大量 Stream
Reset Exception,这也就是为什么在上游 API 的同学看来,他们的接口一切正常,而我们却发现接口的响应时间超过 500ms 的原因。
在此我准备了最小复现问题的 demo,可以直接 clone 下来:
git clone https://github.com/mark4z/rpc-benchmark.git
cd rpc-benchmark
docker-compose up一个小巧但好用的轻量压测工具 https://github.com/mark4z/hey
对于一个后端同学来说,jemter 太重了,wrk 刚刚好,但是不支持 Http2!!!
在这里,介绍一下 hey,支持 wrk 的所有功能,同时支持 Http2,我还为这个工具增加了实时显示压测进度的能力。
安装起来很容易,如果你本地有 go 环境,执行下列命令即可(我有时间会简化下安装方式的,下次一定!):
go install github.com/mark4z/hey@latest
通过 Http1.1 协议压测对应接口
Summary:
Total: 30.0101 secs
Slowest: 0.2814 secs
Fastest: 0.0012 secs
Average: 0.0147 secs
Requests/sec: 9899.7792
New connection: 100
Response time histogram:
0.029 [190818] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.057 [11493] |■■通过 Http2 协议压测对应接口
hey -c 100 -z 30s -m POST -d "1" -h2 https://localhost:9998/delaySummary:
Total: 30.0161 secs
Slowest: 0.3233 secs
Fastest: 0.0014 secs
Average: 0.0254 secs
Requests/sec: 4046.8258
New connection: 4495
Response time histogram:
0.034 [89301] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.066 [21109] |■■■■■■■■■
0.098 [5277] |■■
Error distribution:
[4117] Post "https://localhost:9998/delay": http2: Transport: cannot retry err [http2: Transport received Server's graceful shutdown GOAWAY] after Request.Body was written; define Request.GetBody to avoid this error我们成功复现了问题,可以看到在用 nginx 作为反向代理时,http2的性能表现居然比 http1.1 差了一倍!!!同时,在压测过程中,也出现了上文提到的 Stream Reset Exception,即服务端发送了 GOAWAY 主动关闭了连接,从压测结果来看也能看到 New connection: 4495,是 http1.1 的十倍有余。
众所周知,创建 https 连接是非常耗时的,那么问题就在这里了。
NGINX 的参数问题
通过上文我们发现了 NGINX 作为上游频繁关闭 http2 的连接,导致了性能严重下降,NGINX 有一个默认配置,在一条连接上最多可以进行 1000个请求。
server {
listen 10000 ssl http2;
keepalive_requests 1000;
}这里的参数初步看起来很正常,对于 http1.1 100 并发下新建一批连接可以发送 100*1000=100000 个请求,所以 TPS 是正常的。
但是,对于 http2 来说该参数的单位是 stream,即一次 req+res,也就是一批连接(对于 http2 无论多少并发只需要 1 条连接)仅可以发送 1000 个请求,是 http1.1 的 1/100!!!!
在 http1.1 下,如果请求数是 100000,那么第一批创建的 100 个连接就可以完成所有请求,所以 TPS 是正常的。
在 http2 下,如果请求数是 100000,那么第一批创建的 1 个连接只能完成 1000 个请求,也就是说需要创建 100 批连接,这需要大量的 CPU 和时间
细心的同学可能会发现,《创建100批连接》这个形容有点怪,这是因为常用 http client 的连接池复用机制。
其原理是:当用户发起请求时:检查是连接池内否有符合要求的链接(复用就在这里发生),如果有就用该链接发起网络请求
如果没有就创建一个链接发起请求。
对于 http2,当连接池没有合适的链接时,会创建新的链接,在并发情况下,会创建一批链接而不是一个,这会表现为突然创建了 100 个链接, 然后将第一个链接放回连接池,剩下的 99 个链接直接被关闭。在 nginx 的默认配置下,这样的大批量创建链接并关闭会发生多次。这也是上文这个使用 http2 压测创建了 4000+次链接而不是 100 个的原因。
问题总结及解决方案
总而言之,问题就在于 NGINX 的 keepalive_requests 参数,这个参数的默认值是 1000,对于 http1.1 来说,这个值是合理的,但是对于 http2 来说,这个值是不合理的,应该根据情况调整的大一些。
在这里,我将 keepalive_requests 的值调整为 100000,然后重新压测,发现性能已经恢复正常了。
一点个人感想:
NGINX 是个很优秀的流量网关,但是由于扩展性和功能上的问题,往往会形成 NGINX+API Gateway 的模式,虽然也有一些基于 nginx+lua 的轻量解决方案,但是不够纯粹,性能也会受影响。
不妨试试 envoy 这个后起之秀吧,阿里基于 envoy 开发了 higress,可以把流量网关+API Gateway 的功能都集成在一起,性能也很不错。
最后,让我们给俄罗斯开发者开源的 NGINX 致以崇高的敬意。
hey -c 100 -z 30s -m POST -d "1" -h2 https://localhost:9999/delaySummary:
Total: 30.0032 secs
Slowest: 0.5792 secs
Fastest: 0.0012 secs
Average: 0.0103 secs
Requests/sec: 9725.2897
New connection: 100
Response time histogram:
0.059 [291576] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
Latency distribution:
10% in 0.0048 secs
25% in 0.0068 secs
50% in 0.0089 secs
75% in 0.0116 secs
90% in 0.0162 secs
95% in 0.0212 secs
99% in 0.0338 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0000 secs, 0.0000 secs, 0.0309 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0030 secs
req write: 0.0000 secs, 0.0000 secs, 0.0025 secs
resp wait: 0.0000 secs, 0.0012 secs, 0.5451 secs
resp read: 0.0000 secs, 0.0000 secs, 0.0020 secs
Status code distribution:
[200] 291790 responses文章作者: Mark4z Lv