标准输入/标准输出/标准错误
进程的文件描述符的前 3 项已经被默认使用了。
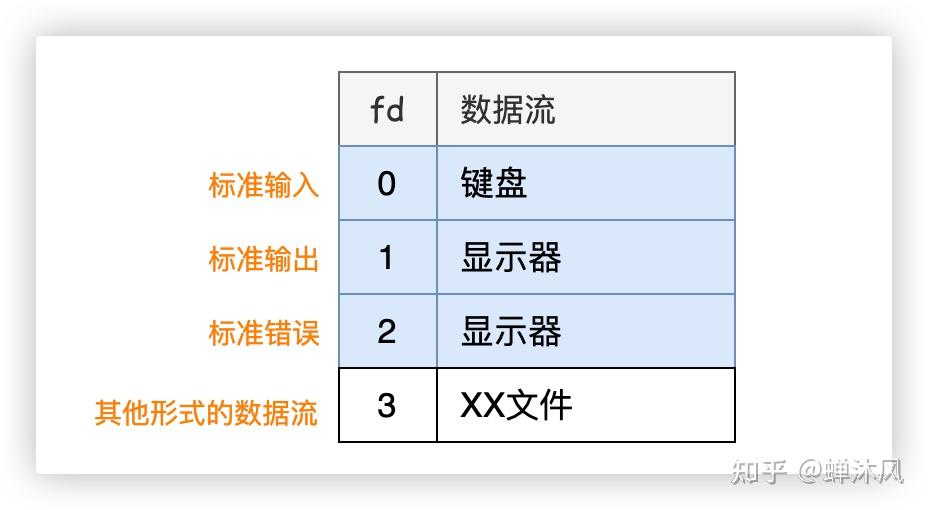
0:标准输入(stdin)1:标准输出(stdout)2:标准错误(stderr)
这些名词怎么理解?
我们在 Java 中使用 new Scanner(System.in) 接收从键盘的输入,使用 System.out.println() 向显示器写数据,对应 C 语言分别是 scanf() 和 printf()。
需要明确的是, 函数并非直接使用键盘和显示器,而是使用了标准输入和标准输出 。
说得再通俗一点就是,进程生来就有一个耳朵和两张嘴,耳朵用来接受 标准输入 里的数据,一个嘴往 标准输出 里边“说话”,另一张嘴往 标准错误 里边“吐槽”。
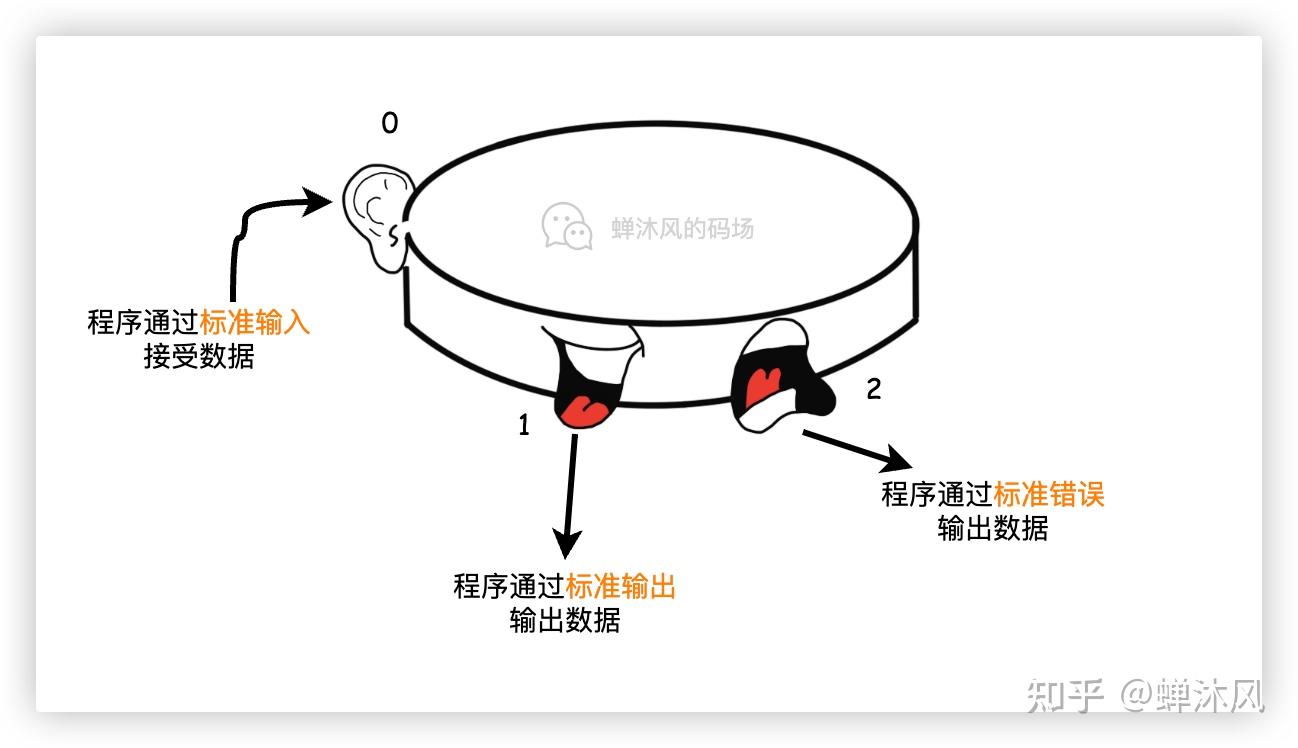
函数并不知道数据从哪里来,也不关心数据要到哪里去,它们只需要从 标准输入 读数据,向 标准输出、标准错误 中写数据就行了。
这就是抽象啊,朋友们!
默认情况下,操作系统会把所有键盘输入都发送到 标准输入,会把从 标准输出、标准错误 中读到数据发送到显示器。
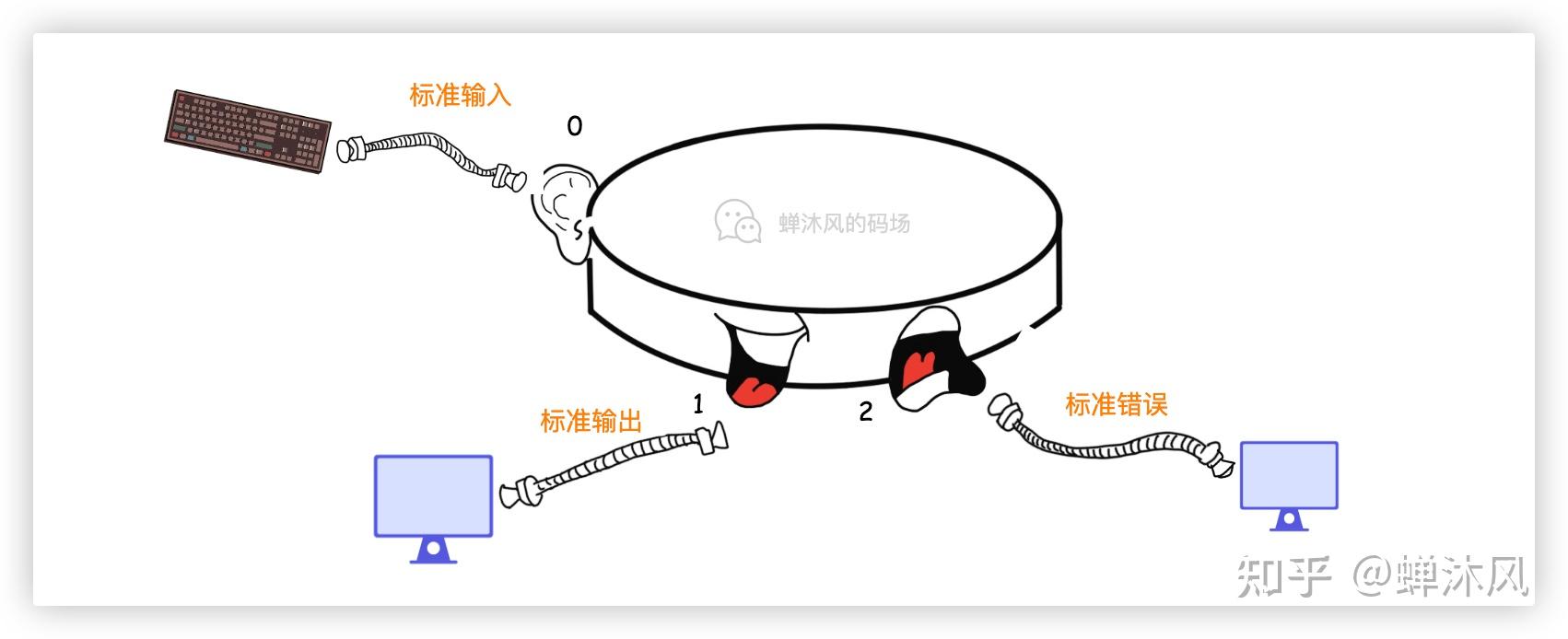
为了方便表示,下文不再将全局文件表画出,而是用一张表来简化表示文件描述符和数据流之间的对应关系。
接下来我们就可以解释文章开头提的问题了。
输入输出重定向
标准输入/输出/错误 在描述表的位置虽然是固定的,但他们指向的数据流是可以改变的。
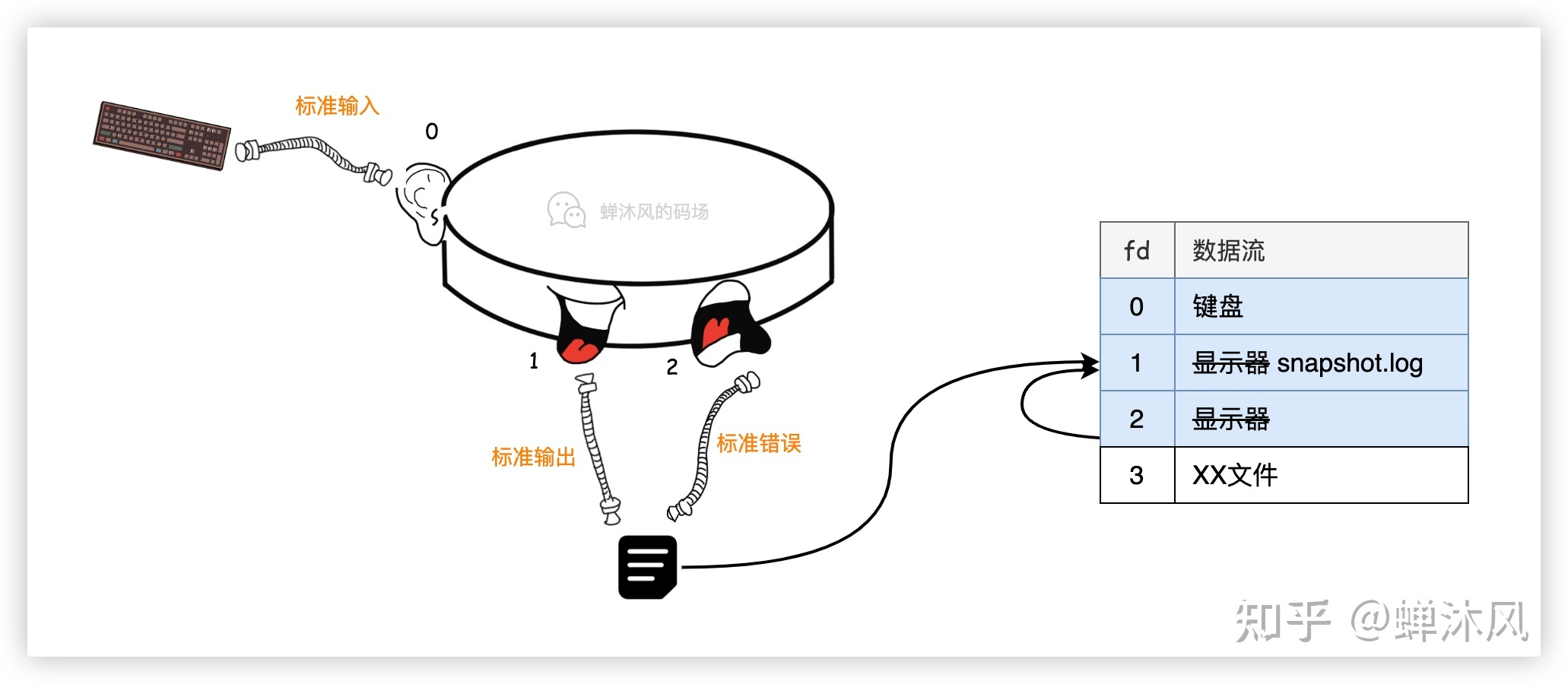
java -jar snapshot.jar > snapshot.log 2>&1 &这条指令的意思就是将 snapshot.jar 程序用 > 运算符重定向标准输出,由原本的指向显示器改为 snapshot.log 文件。
2> 是用来重定向标准错误,因为 标准错误 在描述符表中的 fd 就是 2,同样,其实重定向标准输出也可以表示为 1>,不过一般简写为 >。
标准错误 和 标准输出 可以重定向到同一个地方,比如指令中的 &1 表示的就是 标准输出,2>&1 的含义就是重定向标准错误到 标准输出 表示的数据流中。
>& 表示重定向逻辑。