本文是 做远程设计那点儿事儿 系列文章第二篇,讲以下客户端发送过程的性能优化探索。
众所周知,远程设计底层是用的 RPC 进行的远程通信,往底层讲是 http 协议 + jdk 序列化方案组合成的一套 RPC 调用方案。
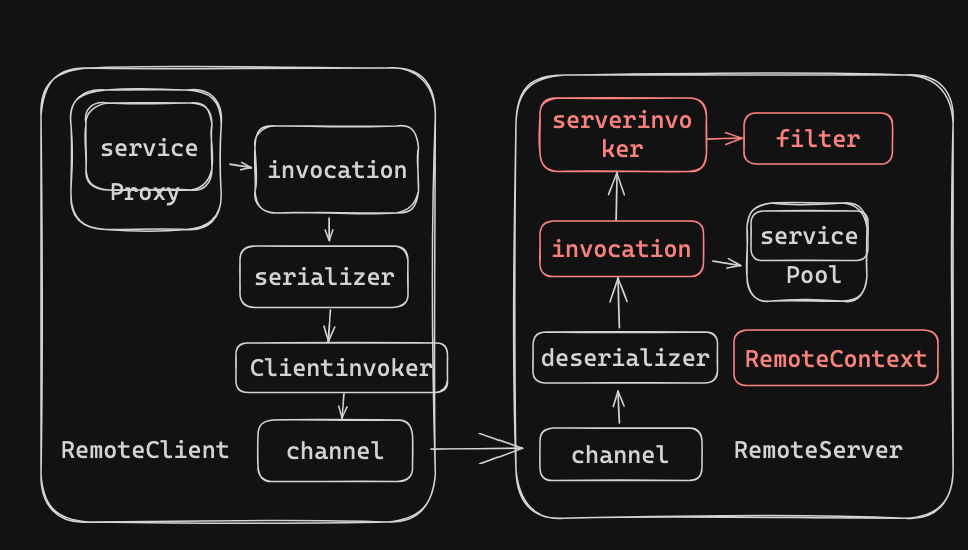
整个的框架非常简单。简单来说就是
通过代理的方式,将方法调用序列化为二进制数组,然后构造为请求,然后发送到服务器后,反序列化为对应的方法和参数,然后调用即可。
基本等同于下图
那么,在不考虑难以预知的卡顿场景,比如网络慢(环境因素),数据量大(比如客户的配置很大之类的,当然这样的场景本身就需要考虑是不是传输的数据不对)的场景下,有没有一些通用方案可以加快远程设计的性能呢? 比如切换协议,但是切换协议本身的成本是比较大的,要考虑客户部署的适配情况,在没有关键阻塞点的情况下,一般不会考虑切换协议的方案。
基于此,综合建议后,找出以下几种方向,进行探索。
1、 减少请求数量
2、 减少 IO
这个就不详细展开了,说白了就是尽量的零拷贝,但和我们目前的远程关系不大,想要了解的,参见 Java 的 MappedByteBuffer 读写文件, 3.3.2 零拷贝 - 磁盘消息文件的读取
3、 减少请求大小
- 序列化方式
- 压缩方案
减少请求数量
由于我们目前是使用的 http 协议作为通信协议,每一次通信都需要建立 TCP 连接(3 次握手都讲烂了)。
之前就遇到一个 客户问题 网络因素导致远程设计编辑图表卡死。, 经过测试,场景如下
- 下载一个大文件 130mb, 耗时 40s,
- 下载 500 个小文件,每个请求大概 500ms, 总共耗时 250s
客户本身的网络一般,500 个请求,放大了建立连接的耗时,从而导致该问题。
基于此,当然第一方案是直接减少请求数量。将 500 个请求合并成一个,等价于大文件的方案即可。
另外,要考虑业内有没有通用的减少请求数量的方案, 比如批量请求,将多个请求合并为 1 个这种。
批量请求
经过对比,找到两个比较类似的,1 个是 dubbo, 1 个是 kafka.
先看 dubbo
见其中一个 pr Dubbo 性能调优总结文档 · Issue10915 · apache/dubbo · GitHub
里面讲了做的批量发送优化
简单概括,原先的逻辑为以下这种
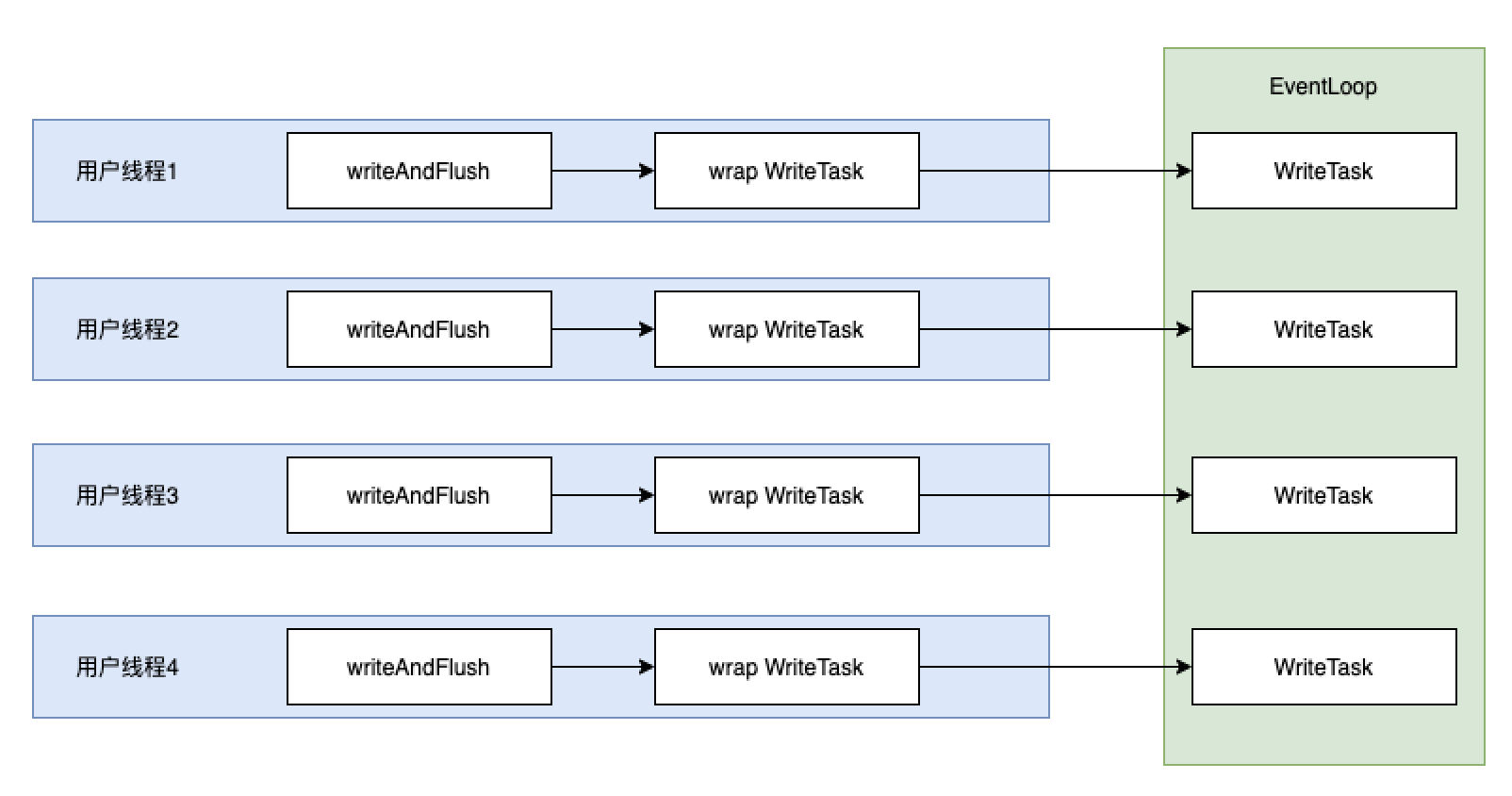
用户线程会不断的提交 writeTask 任务到 EventLoop 中。然而每一个 writeTask 任务都是新创建的,导致 EventLoop 线程需要被调度,然而每次调度的时候只能处理一个 writeTask 任务。
基于此问题, 后面改造成了如下的效果
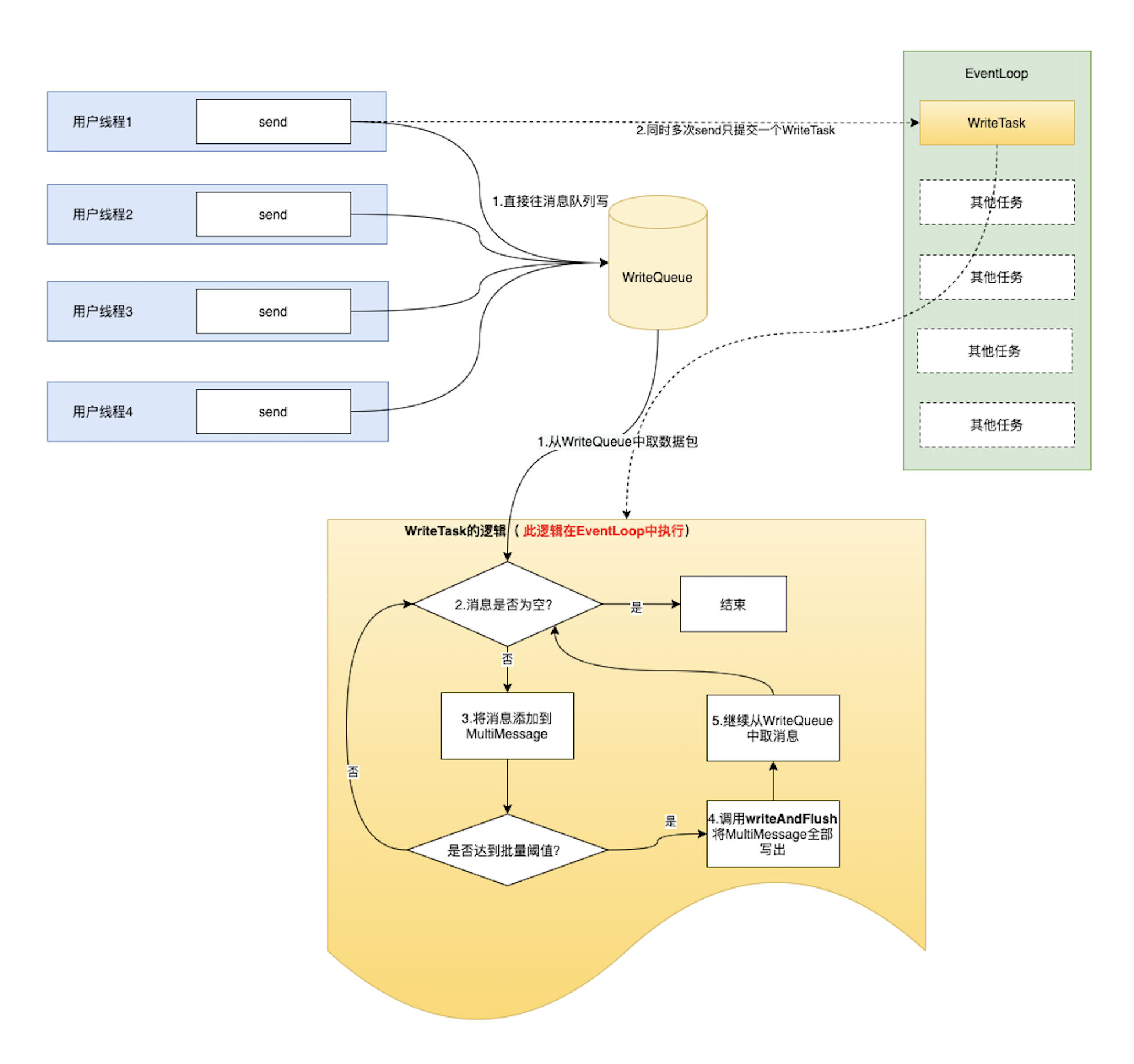
即用户线程将任务写入 writeQueue 这个中间件中,当调度 EventLoop 的时候,writeTask 从 writeQueue 这个中间件里面取任务,然后执行,避免线程调度的存在。
总结
总结一下,就是在当前 EventLoop 在执行时,message 进入任务队列 writeQueue, 然后等待下一次 EventLoop 去调度的时候,writeTask 开始不断的从 writeQueue 里面取出 message, 一次性发送,从而避免线程频繁切换的开销。
然而,我们的远程使用的 http 协议,直接通过 httpclient 发送对应的请求,每一个请求都是一个新的连接,并不会要考虑请求阻塞,然后排队类似的事情。所以这个方向 pass
再看 kafka
kafka 本身是有一个 消息发送延迟机制 ,如下图
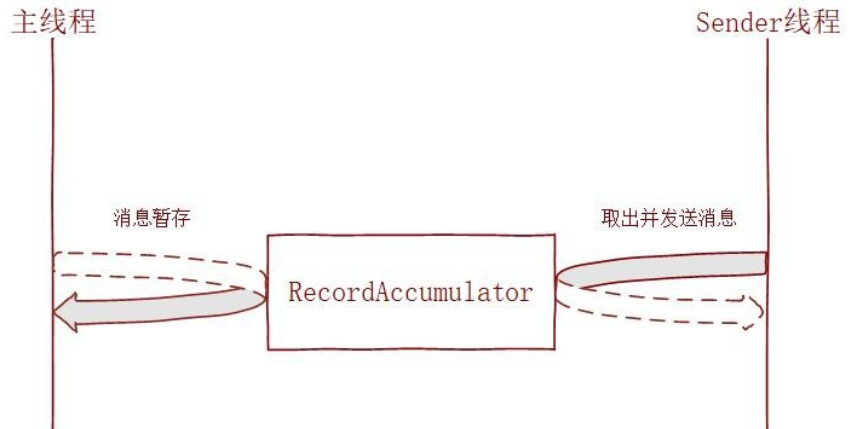
具体流程是 kafka 生产者使用批处理试图在内存中积累数据,主线程将多条消息通过一个 ProduceRequest 请求批量发送出去,发送的消息暂存在一个队列 (RecordAccumulator) 中,再由 sender 线程去获取一批数据或者不超过某个延迟时间内的数据发送给 broker 进行持久化。
优点:
- 可以提升 kafka 整体的吞吐量,减少网络 IO 的次数;
- 提高数据压缩效率 (一般压缩算法都是数据量越大越能接近预期的压缩效果);
缺点:
数据发送有一定 延迟, 但是这个延迟可以由业务因素来自行设置。
总结
缺点是延迟,这是不可以接受的,本身就是为了提高实时性的优化,如果搞成延迟,完全的舍本逐末。
总结
以上两种批量发送思想都是在各自的领域比较重要的存在。
减少线程切换的思想,在 dubbo / grpc 都广泛应用。
延迟后,批量发送,在消息队列上是广泛使用的,
但是以上都不适用于我们当前的远程 rpc 逻辑。
序列化方式
传输的数据,作为网络中重要的组成部分,对序列化的选型,尤为重要。
序列化方案需要考虑
- 性能
- 安全性
- 兼容性
- 灵活性
- 可读性
- 跨平台
- 稳定性
然后,从耳熟能详的序列化方案中选出以下几个进行相关纬度的考量
- fury
- protobuf
- kryo
- json/jackjson
- java-built-in
性能
参考 Home · eishay/jvm-serializers Wiki · GitHub
比较靠谱的 jvm 序列化基准测试,结果如下
| create | ser | deser | total | size |
|---|---|---|---|---|
| fury | 56 | 269 | 239 | 508 |
| protobuf | 198 | 875 | 527 | 1402 |
| kryo | 51 | 917 | 1044 | 1960 |
| json/jackson/databind | 49 | 1344 | 2053 | 3397 |
| java-built-in | 57 | 5357 | 29617 | 34974 |
fury 一骑绝尘,速度和大小都遥遥领先。
protobuf 非常的稳定
json 中规中矩,但也比内置的 java 方式小了大概 10 倍, 快了 10 倍
本机测试中,以以下 Bean 作为基准进行序列化性能如下
public class User implements Serializable {
private static final long serialVersionUID = 2566816725396650300L;
private long id;
private String name;
private int sex;
private LocalDate birthday;
private String email;
private String mobile;
private String address;
private String icon;
private List<Integer> permissions;
private int status;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}
| 框架 | 200w Deserialize(ms) | 200w Serialize |
|---|---|---|
| fury | 68ms | 148ms |
| kyro | 347ms | 4061ms |
| protostuff-runtime | 307ms | 5450ms |
| java-built-in | 9040ms | 14506ms |
安全性
安全问题描述
详见 Java 中的反序列化漏洞
这里就不赘述了, 在不同情况下, JDK 和 jackson 都有序列化安全问题。
但是 jackson 触发条件。
- 调用了 ObjectMapper.enableDefaultTyping()函数;
- 对要进行反序列化的类的属性使用了值为 JsonTypeInfo.Id.CLASS 的@JsonTypeInfo 注解;并且该值为 Object
- 对要进行反序列化的类的属性使用了值为 JsonTypeInfo.Id.MINIMAL_CLASS 的@JsonTypeInfo 注解;并且该值为 Object
总结
只要是 JDK 序列化可能都不可避免的存在安全问题。曾经想在 JDK9 完全移除序列化,后面被终止,但也可以看到 JDK 序列化存在的问题
而 fury 协议在完整的 JDK 支持下,100%兼容 JDK 序列化:支持 JDK writeObject/readObject/writeReplace/readResolve/readObjectNoData/Externalizable 序列化 API。 因此存在序列化安全问题。
但是于此同时, fury 支持跨平台协议,本协议下, fury 是不兼容 JDK 序列化的,所以可以保证安全性(可能?源码还没看)
kryo 同理
protobuf 因为是自身实现的一套协议,是需要自己写一套元文件 .proto , 因此安全性较高
稳定性
考虑到 fury 刚刚发布,7.15 号,详见 furyio.org/zh/blog/list, 在试用的时候,还遇到过 BUG, 并且提了个 issues, [JavaScript] If Serialized by JS, Deserialized in Java will failed · Issue703 · alipay/fury · GitHub 因此稳定性欠佳。阿里的东西,大家懂得都懂。
其他方案都比较成熟,因此稳定性较高。
灵活性
protobuf 可以通过 protostuff-runtime 来进行动态创建 schema , 一定程度上提高了灵活性。但性能会有所下降。
跨平台
kryo 只支持 jvm
其他框架支持多种。
json 完美的支持
兼容性
json 不需要考虑,
protobuf 有着良好的兼容性。
kryo 采用自定义和兼容 JDK 的方式保证兼容
- Kryo 为了保证序列化的正确性,在遇到定义了 writeObject/readObject/readObjectNoData/writeReplace/ readResolve 的对象时,会调用 JDK 的 ObjectOutputStream 和 ObjectInputStream 进行序列化。
- Kryo 提供了一些通用序列化器,它们采用不同的方法来处理兼容性。可以轻松开发其他序列化器以实现向前和向后兼容性,例如使用外部手写模式的序列化器。
java-built-in使用 id 来保证兼容性。
可读性
这个主要是考虑到定位问题的角度。
json 无疑是有且仅有的选项。
总结
java-built-in 完全是不可用,安全性差,性能差,样样都差,差点被自己的亲妈抛弃了。
protobuf 是完美的微服务中的协议之一。google 背书,稳定性强,性能高,跨平台,协议简单。
json 是需要可读性,灵活性,并兼具一点点性能的完美选择。更主要的是适用范围广,没有语言会不支持 json
压缩方案
压缩算法,讲究压缩比和压缩速度。
考虑到 gzip 的普适性和高效,比如在浏览器和服务器交互的场景上,原生支持的 gzip 编码,所以无论怎么选型都必定考虑采用兼容 gzip 的算法。gzip 的原理在这里就不详细描述,有兴趣的可以移步 gzip 压缩算法原理
见上面这篇文章中的性能比较,各种压缩算法,压缩比并没有完全碾压的存在,基本上是依赖于设定的等级,然后会等比例的提升时间。
而在兼容 gzip 的算法中有一个 pigz 算法较为突出。
其最大的作用就是并行策略,可以将 gzip 的性能提升 50% 以上
不过 pigz 本身是 c 实现的命令,不适用于 Java
不过凭借着关键词 并行 gzip java , 同样找到了替代品(Java 的库真是太全了,🥹)
即 migz, 经过测试,至少相比原生的 gzipxxstream 性能提升 50% 以上
但是与此同时,cpu 占用率相比原生高很多。
在我本机测试,原生平均 20%,使用 migz 至少 50% 以上的占用率。所以需要谨慎使用。
说到谨慎使用,又不得不提另一个话题,什么时候使用 gzip。
目前远程是发送 gzip , 返回 gzip 。不考虑数据量大小。
考虑到 gzip 原理,在小文本的情况下,压缩率不一定更好。并且还要加上压缩,解压缩的时间,可能会比原来更加的差。
参考 Nginx 和 Tomcat 的 gzip 压缩配置, 需要设定最小的压缩体积,超过才开启,否则默认关闭。